

2× – nine months later: We did it
You can too.

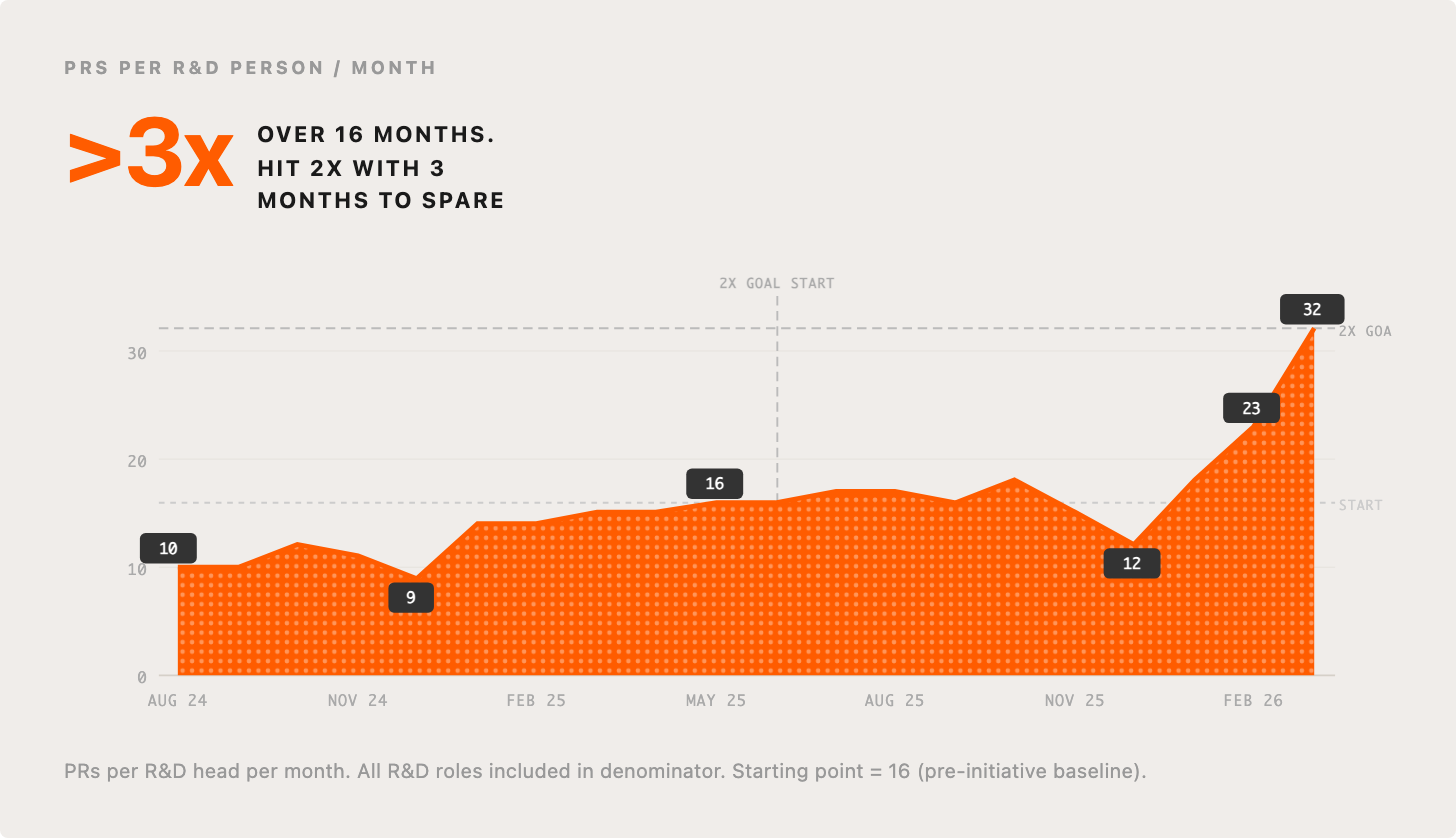
Nine months ago, we set a very deliberate goal to 2x the productivity of our R&D org within 12 months. We’d already seen early benefits of AI-assisted engineering, but knew there was so much more coming. My instinct at the time was simple: even if AI progress stalled, it was already good enough for us to hit this goal, but we must deliberately chase it and overcome all obstacles in our way, as opposed to being passive and hoping it happens to us.
This level of public accountability was scary, and it wasn’t always clear to me that we’d pull it off, but…. we did it, with time to spare. In fact, looking back over 16 months we’ve 3x’d and I see no signs of plateauing. I anticipate we will 2x again in a short number of months. I want to give you an unfiltered look into the impact we’ve seen holistically for our product and our org, and how to go about making similar changes in your own company.
This will be a multi-part post. This first part will mostly be about what we’ve seen. In the next, I’ll talk about our messy journey, some of the lessons learned along the way, and what’s coming next.
A culture optimized around moving fast
Our culture has always been optimized around building great product, fast. If you think of your R&D org as a factory, ours was a fairly impressive factory, one others would aspire to replicate. However, technological change, in this case with AI, can very quickly raise the ceiling of what is possible, and you must modernize your factory to not fall behind. We’ve never had a shortage of product vision but have always been constrained by executional capacity. AI unlocks an abundance of capacity, dramatically amplifying our ability to execute against our product vision.
We aspire to be at the forefront of exploiting what is possible with AI, and as a result, more quickly and efficiently build our vision for the future, solving customers problems faster than anyone else. Ideas that would previously take weeks or months can now take hours or even minutes.
We aren’t the only large R&D organization deliberately chasing this kind of outcome, and indeed, I respect and applaud large organizations who have also gone really hard (e.g. this wonderful post shared a few days ago by Ramp). But I’ve also talked to enough people to know that most are struggling to make the right changes or see close to the level of impact that’s possible. I hope by being transparent about our journey we can inspire others to follow a similar path and encourage others to push us to go further too.
For context, while we are going through an exhilarating rebirth phase, we are nonetheless a big, old, beautiful, messy company. Thirty thousand businesses rely on us for how they run their business. We’ve almost ~8.5 million lines of application code (across Ruby, TS, JS, Python, Go, Swift, ObjC, Kotlin, Java). Our PlanetScale datastores alone peak above 2 million QPS. Over the last 24 hours, we ran 2,539 Continuous Integration jobs, each consuming days of compute time, and made 313 distinct automatic deployments to production. We see velocity as a strong driver of stability. There are ~500 people building and operating the product and software that we run, these people are spread across four offices in two continents.
In short, we are not a small startup with the benefit of a blank page, but we know full well that if we don’t adapt aggressively we are heavily threatened by them, and so are you.
There are so many companies similar to us, alive today based on great success in the old world, but dead if they don’t adapt aggressively to the new world. We want to thrive in this new world. And we want to show you it’s possible and inspire you to make the, at times, difficult decisions and changes to achieve it.
Wait, you measured what now?
We measured the number of merged PRs divided by the total number of employees in our R&D org. This particular measure is easy to criticize – are we really going to fall into the trap of just looking at the output of the engineering team in this naive way? This isn’t far off measuring LOC? None of this is done in isolation, our thesis for measuring PR throughput is as follows:
We believe in fast, safe, and frequent shipping. A new engineer on the team will ship to production on their first day. Shipping is our heartbeat.
Conceptually, our org is a factory for producing high-quality increments to our product. These leave the production line as merged PRs (pull requests). Our job is to increase the throughput of the factory, while maintaining or improving quality and decreasing cost. Time, cost, scope, pick three!
Putting higher expectations on merged PR throughput puts pressure on the whole system, exposing bottlenecks which we then systematically tackle.
We also look at this top-down. What we actually want to optimize is how frequently and how quickly we can go from problem to solve or idea, to solution in our customers’ hands. Both views are useful, but at different zoom levels.
It’s important to highlight precisely how we define our metric, total number of merged PRs, divided by total number of people in R&D (everyone from IC engineers to VP of product design). We divide by all the people, because 1) that’s all the cost; 2) we expect all people to be able to directly and indirectly impact the metric; and 3) it puts healthy pressure on our org design, by default we should assume all our existing org structure patterns are wrong for the new world.
So many people internally and externally get caught up on this question of how to measure this, afraid to measure the wrong thing, or hold back from driving change because they can’t find the perfect measure. My advice to you is to be at peace with potentially imperfect measures, don’t let that hold you back from the outsized outcomes that lie in store.
So, yes, this metric is not quite perfect, but we’ve driven massive movement in it, hit the goal/milestone we set, AND paid close attention to everything else that changed.
I want to give you an unfiltered and transparent view into a range of benefits we’ve seen, that are well within reach if you push for them with determination.
What has been the holistic impact of our AI acceleration?
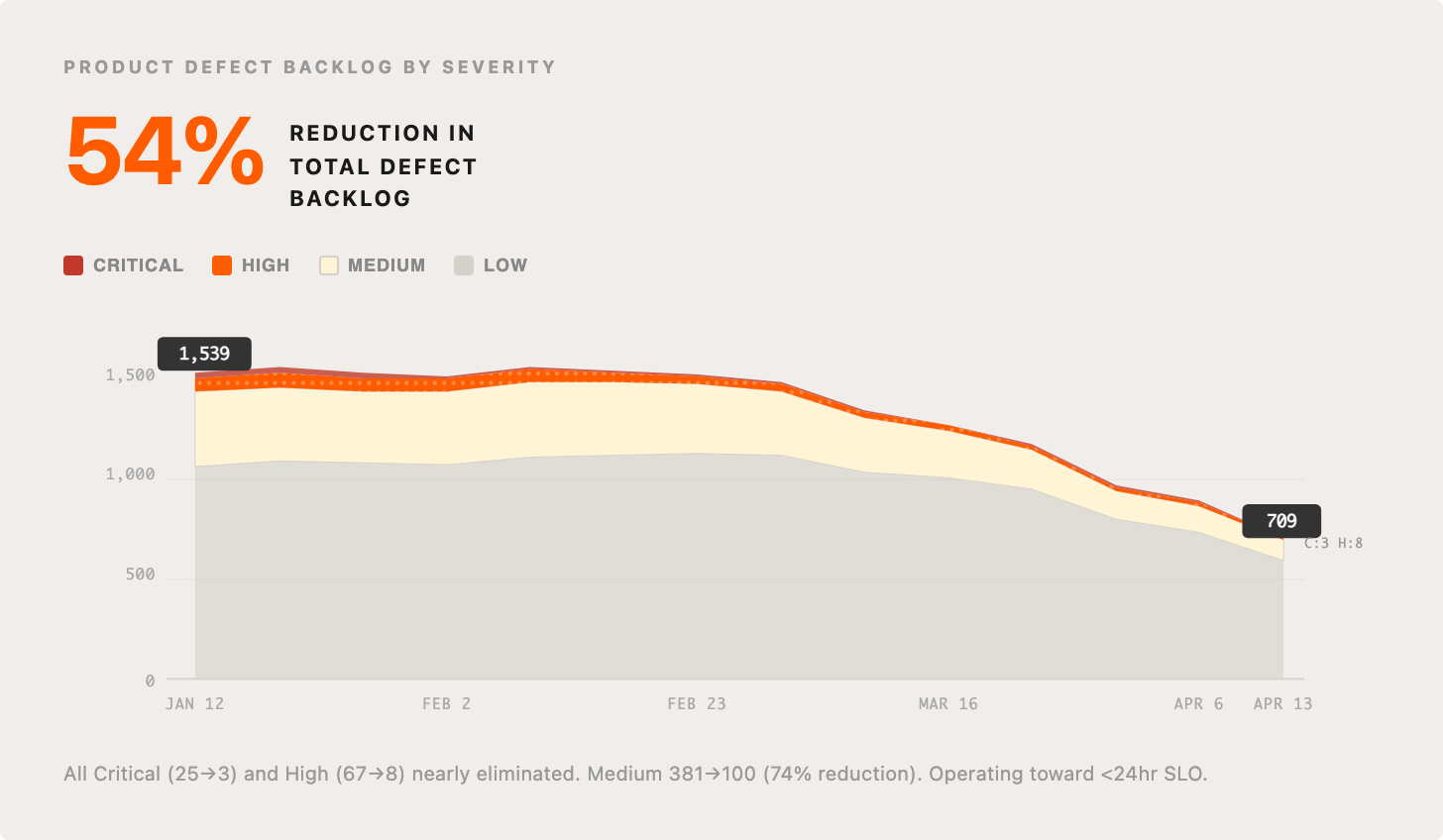
1. Product defect backlog shrunk by 54%
Since the start of the year, we’ve reduced a core product defect backlog by 54%, closing all critical and high defects. We are also on track to imminently close all medium defects. Our intent here is to stop wasting time on the drudgery of prioritization and backlog management, the issue ping pong, etc., and instead attempt to operate around an SLO of fixing all reported issues in less than 24 hours (currently at 10.4% and climbing), and maintaining effectively no backlog. Very few product teams I know have ever achieved this high standard, but it’s now well within reach. All this is obviously a well-deserved win for our customers, and just the start of all the ways they’ll start to feel the impact of our internal improvements.
2. >2x product changes, 39% faster from idea to shipped
We’ve started to see two strong trends. We are shipping more product changes, and we are shipping them faster. This is noisy data, not all product changes are equal in size, scope, etc., you can have spiky months, but it’s directionally indicative. Median time from idea to product change is nearly cut in half, and even if we ignore December, we’ve more than doubled our product changes in March vs January. We are able to say yes to more of the things that matter most to our customers, and be more ambitious in what we aim for too.
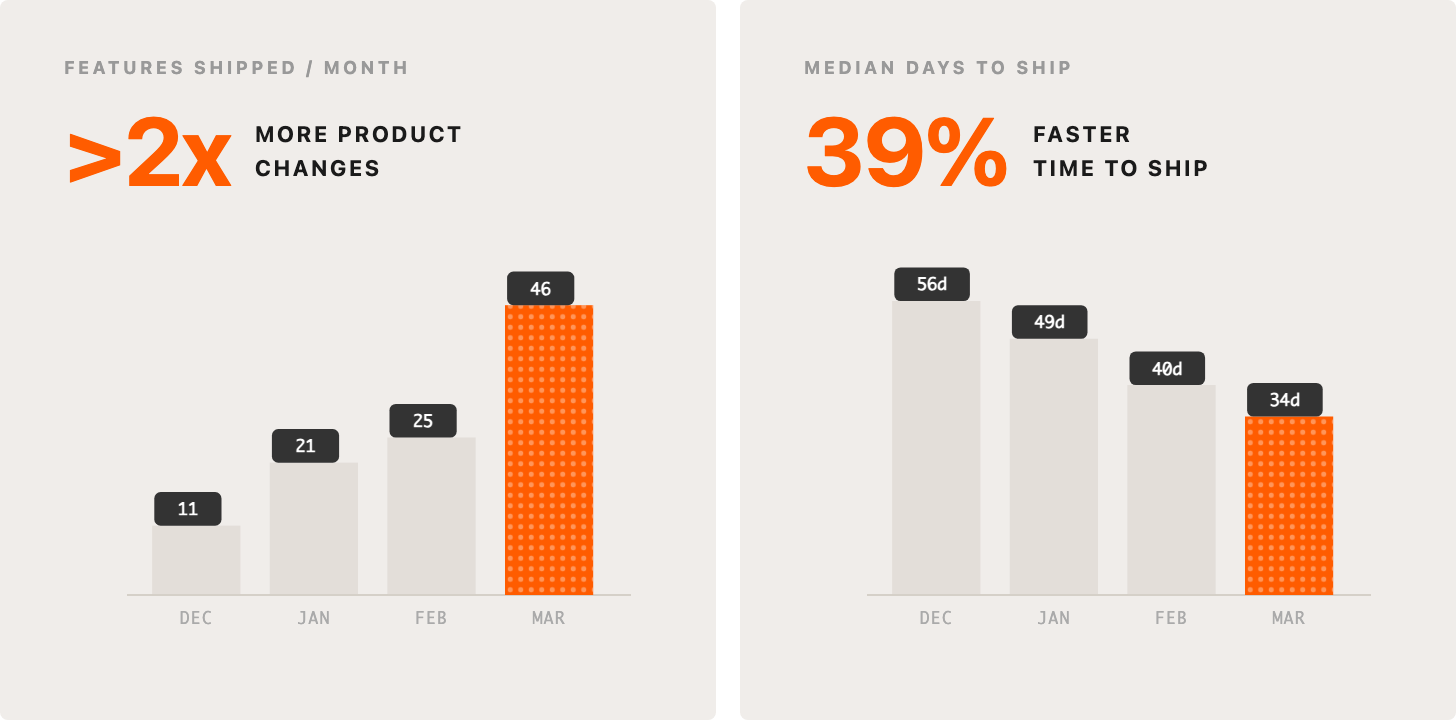
The faster we can responsibly ship, the faster our customers get leading edge capability, the faster Fin resolves their support conversations, and the faster they can grow their own businesses.
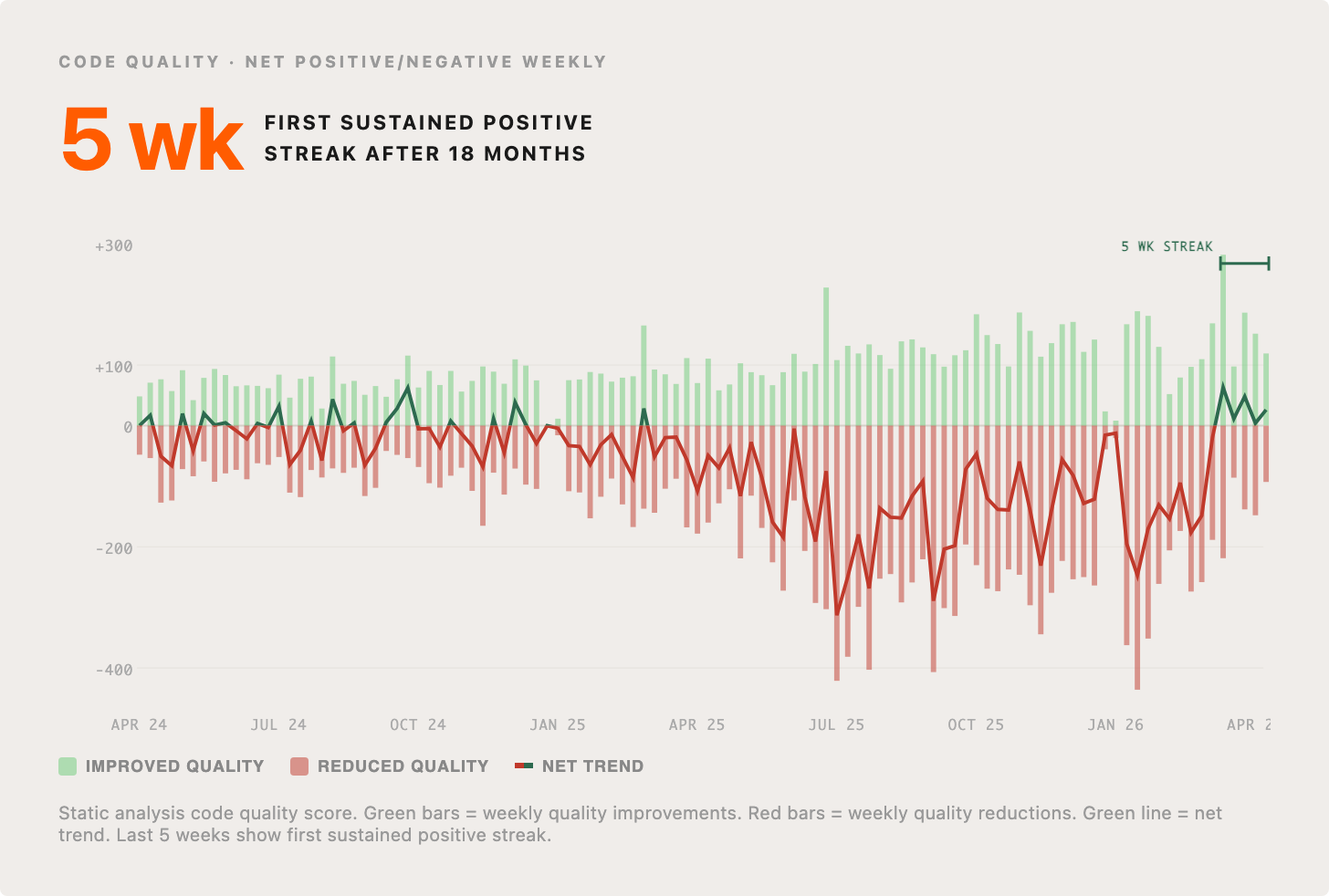
3. Code quality improving, after period of consistent decline
A legitimate worry with the use of coding Agents, is that they won’t write high-quality code and the craft we’ve fought to protect will be undermined by slop cannons. We have a system to rate the structural quality of code contributions using static analysis and various rules/heuristics. It’s clear that prior to agentic coding, this metric would oscillate up and down above the line. As we started to use AI for writing more and more of our code, the overall quality (by this measure) declined. My intuition was that this was inevitable in the short term, but correctable in the medium term, as models and harnesses get better. We are starting to see this and recently had possibly our first ever five-week streak of net positive code quality overall. I’m sure this streak won’t last forever, but my bet is that average quality will continue to trend up.
4. Downtime from breaking code changes down 35%
It’s natural to assume that doubling our deployment throughput means we’re breaking things more often. But that hasn’t happened.
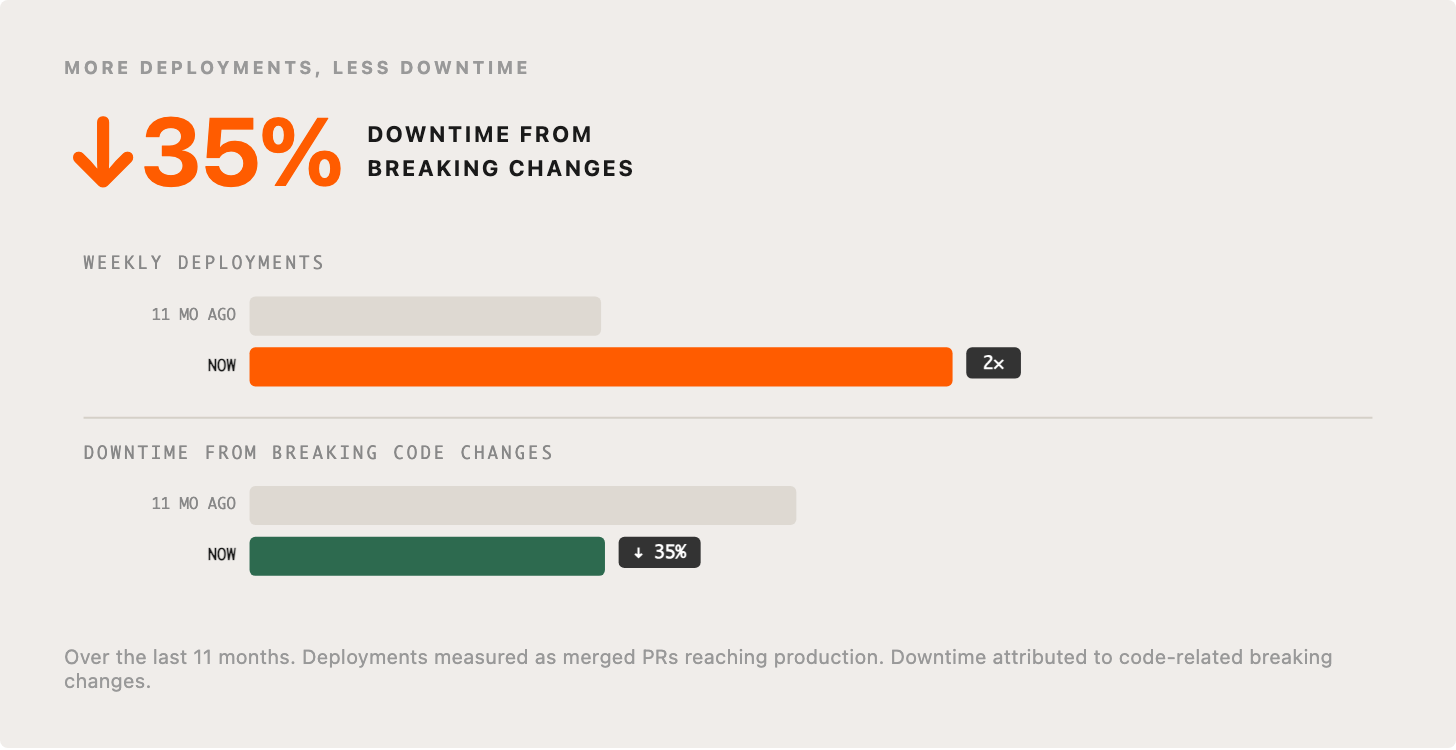
The data shows something even better than “no degradation.” The downtime we can attribute to breaking code changes dropped by 35% over the last 11 months, even as our deployments doubled. Our culture has always been optimized around building great product, fast, but also safely. What’s really happening is that by letting AI handle the mechanical aspects of coding, our engineers have the mental bandwidth to be far more deliberate about architectural quality.
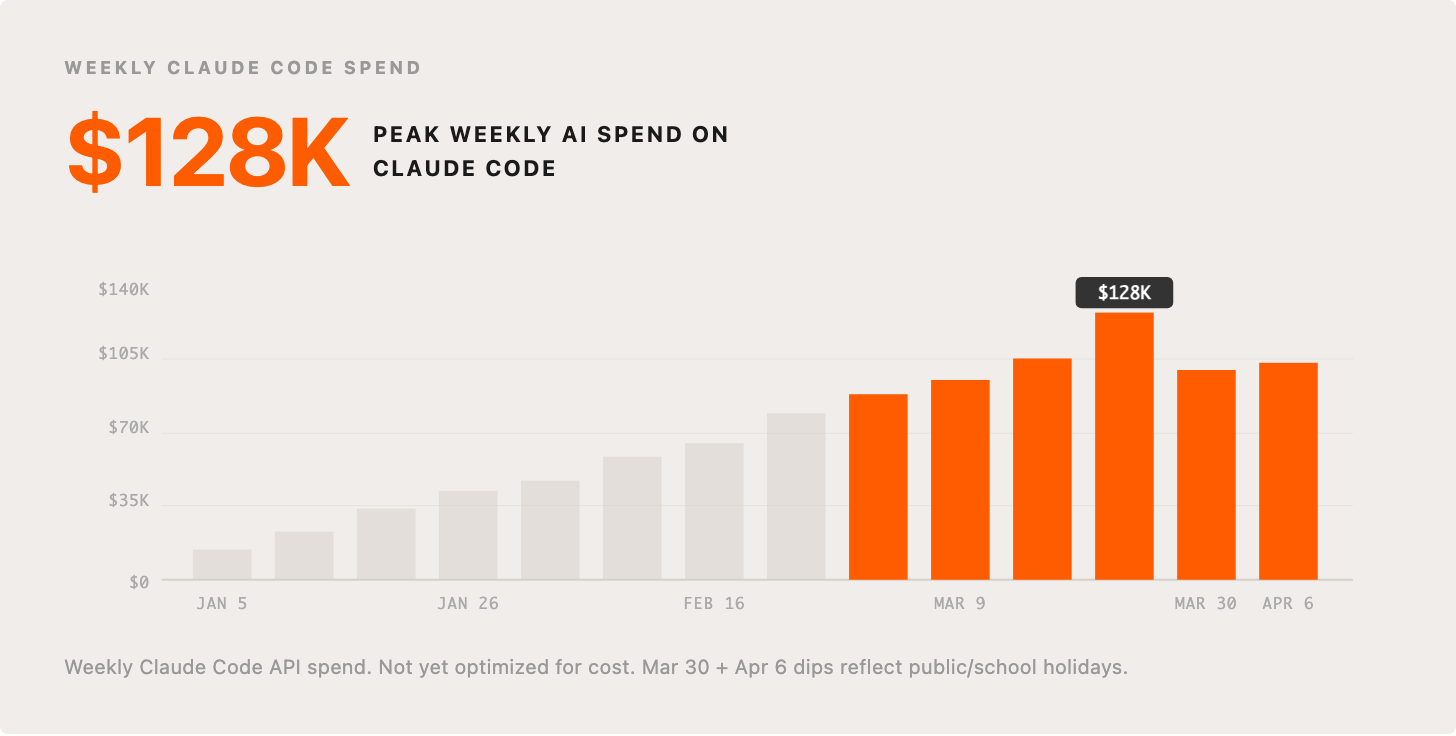
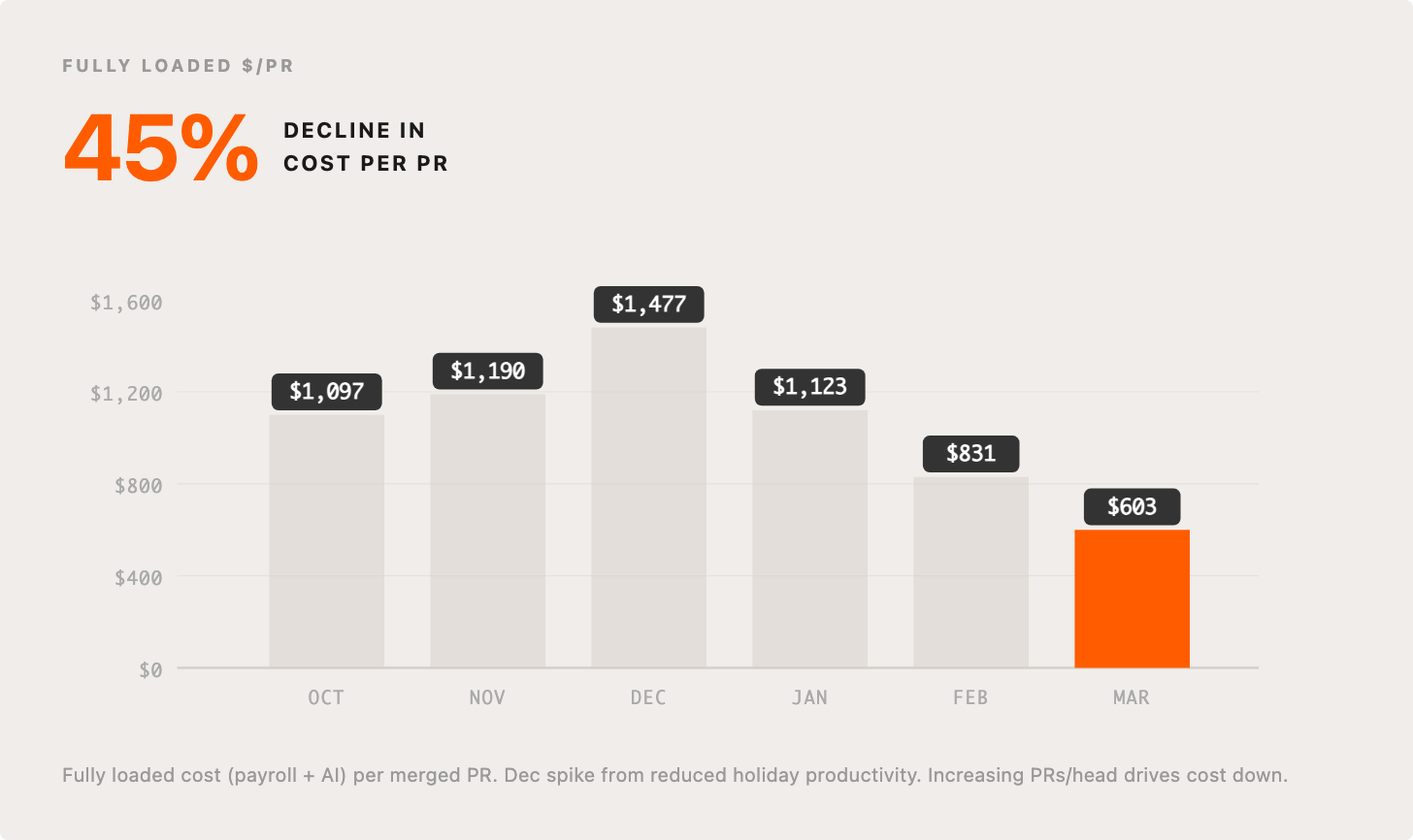
5. AI costs growing exponentially BUT costs per PR cut in half
Our AI spend has been climbing sharply, exactly what we want to see. We’ve not tried to optimize this despite believing there are ample opportunities to do so. For now, our focus is on AI leverage and we believe we are only scratching the surface. This chart is our weekly spend on Claude Code this year. I expect this to continue to grow steadily through the year.
When Agents can do work humans would otherwise do, it’s almost always a huge ROI. One way we look at this is by tracking fully loaded costs per PR. Payroll-related costs massively dominate this, and tend to have strong YoY upward pressure (promotions, pay increases, market adjustments, etc.). However, with ever-increasing PR per head, the overall cost per PR is in a steady decline. December is higher because between time off and other end-of-year stuff, people are far less productive, but the overall trend continues.
6. 93.6% of PRs are Agent-driven
We drove a big behavior change in a short number of weeks. As soon as we made the decision that we’d double down on Claude Code as our primary agentic coding system, we set a goal that within six weeks, >80% of PRs would be driven by Claude Code. We then raised that to 95%, which we are currently hovering just below.
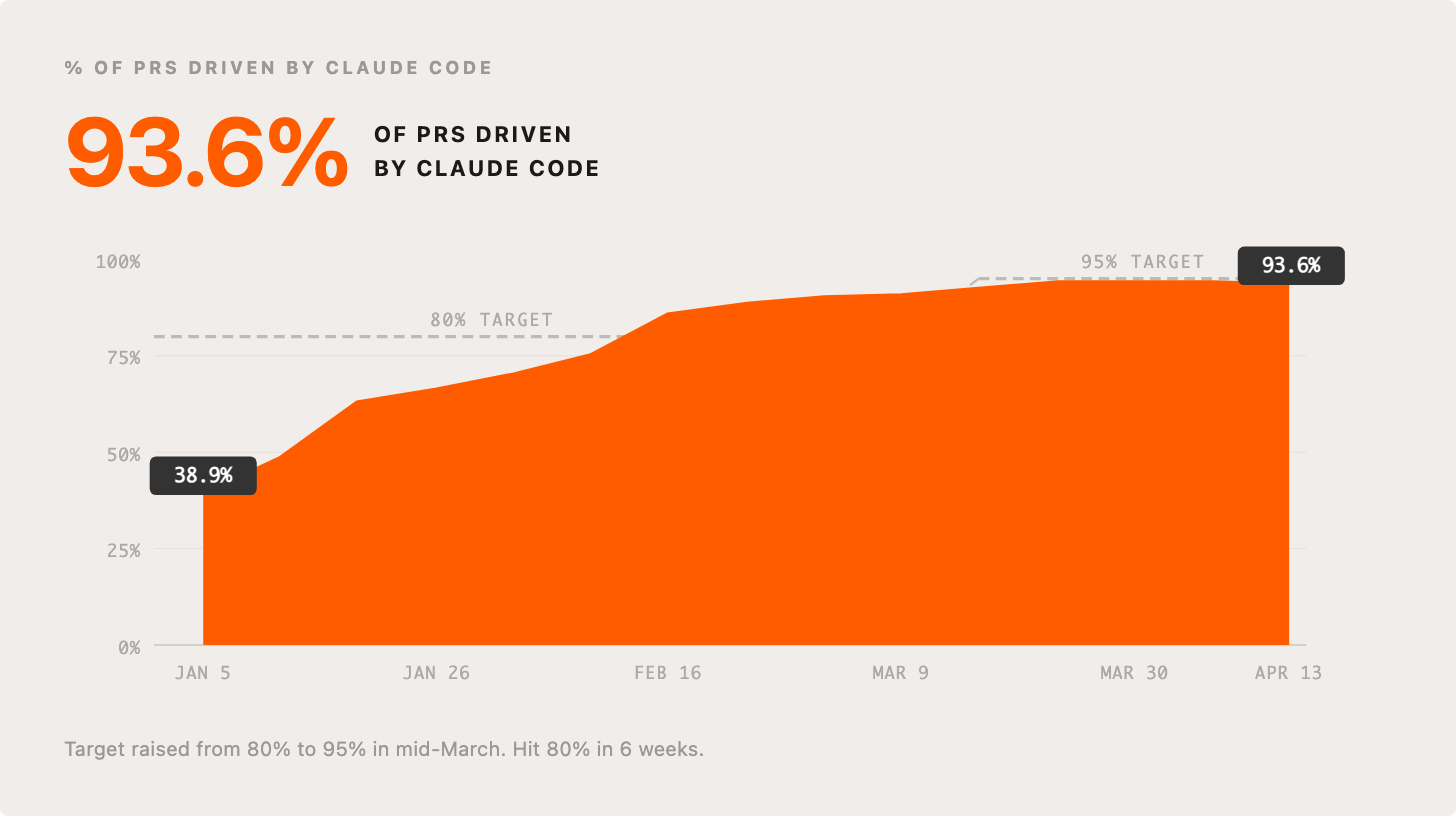
Many of our engineers rarely even use an IDE/editor.
This is all inline and driven by new principles that describe how we should now work. The first and most important is:
“All technical work is becoming agent-first. This is the top priority for R&D.”
We will share our full set of “2x principles” in the days ahead.
7. 19.2% of PRs are now AI-approved. Near-term goal is >50%

Creating PRs isn’t the only part of the “factory” to apply an Agent-first mindset to. With the ramp-up in PRs, unsurprisingly, one of the bottlenecks that gets exposed is PR review and approval. If we want our factory to move faster, we can’t have every increment waiting in a human review queue.
We took an ambitious goal to hit >50% AI PR approvals by the end of April. We’ve started with the lowest risk changes – feature flag cleanups, small bug fixes, focused improvements. Only a few weeks in and we’ve already seen 19.2% of all merged PRs auto-approved with no human reviewer in the loop. The system evaluates roughly 60% of PRs and we expect both coverage and approval rates to climb as we expand the criteria.
This not only reduces the demands on others to spend time on PR review, but reduces the waiting time to get PRs shipped. Auto-approved PRs merge in a median of 14.6 minutes compared to the org median of 75.8 minutes. Eighty-six percent of auto-approved PRs are 20 lines or fewer – exactly the kind of well-scoped changes that shouldn’t bottleneck in review queues.
Perhaps the most striking number: 497 PRs went fully autonomous in the first four weeks Claude wrote all the code, with our AI approval system reviewing, approving the change, and shipping to production. We are also ramping up the percentage of PRs driven entirely by Agents, without humans triggering them.
You’d be right to be anxious about making a change like this, but we are approaching it in a very methodical way, and will share more about our auto-approval approach in a follow-up post.
8. 31% of our org are active contributors to our auto-updating suite of Claude Code plugins
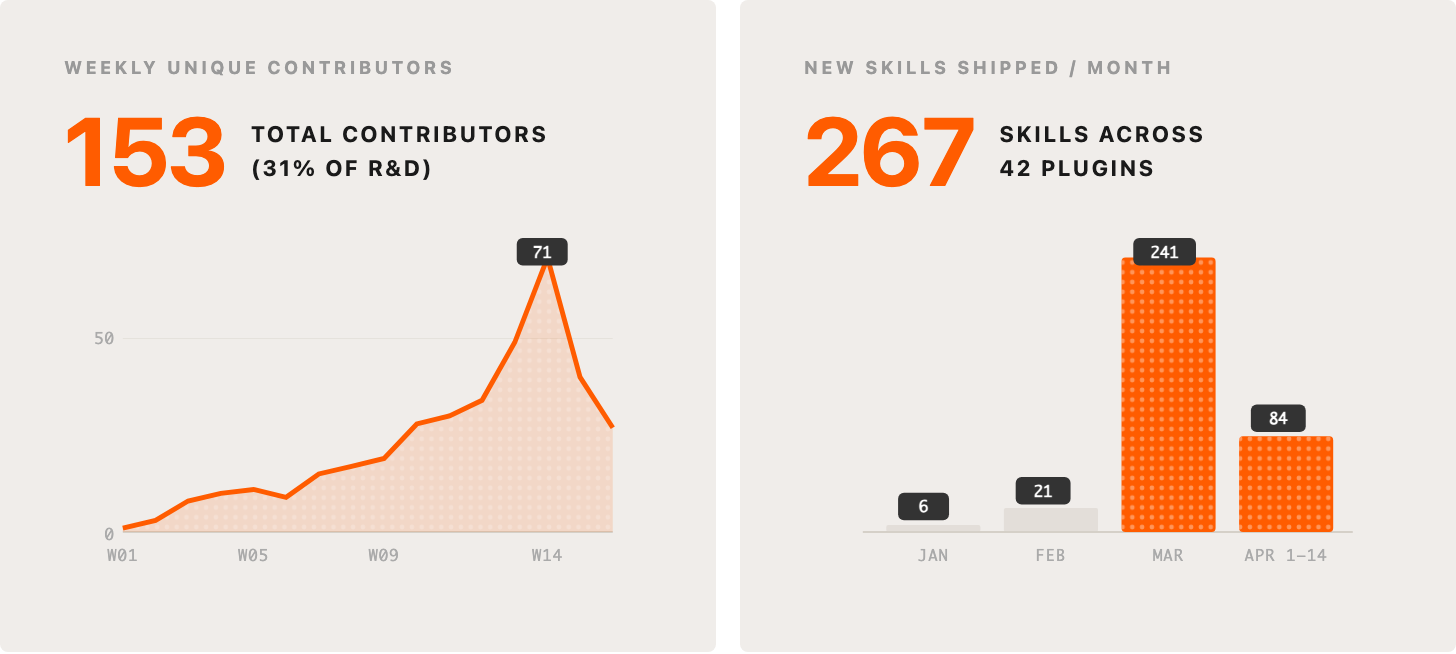
A big turning point in our progress was the decision to go all-in on Claude Code and build a shared platform around it. We spun up a dedicated team (“team-2x”) and created a private plugin marketplace that distributes configurations and skills – specialized capabilities for common tasks – via auto-updating plugins. When someone builds a skill to do a task in the best way possible, everyone on the team immediately benefits. When we improve a skill that everyone relies on, the improvement ships to everyone automatically. In the three months since we started this, our Claude Code plugins repo has become the most actively contributed-to project at Intercom – 153 contributors (31% of R&D) and 267 skills. This isn’t a platform team building for others; modernizing the factory is now part of everyone’s job. Some more details in Brian Scanlan’s viral thread about this.

9. Top 5% of contributors produce 6x the median PR throughput
I still think we are only getting started. We are learning at a rapid pace, but a big area of opportunity is the unevenly distributed nature of progress across our team. There is *huge* latent potential. Some people are really pushing the limit of what is possible, tokenmaxxing, doing really interesting things, while others have only really made incremental changes to how they’re working and don’t see much change in their personal throughput. Ultimately one of the biggest bottlenecks to progress is with humans; how we work together, how we change behavior, etc. We’ve made some great progress and I’m confident we can crack this too, but I want to show a sober view of how unevenly distributed the impact is. In general, the people who are able to spend the most with Claude are having the largest increase in personal throughput.
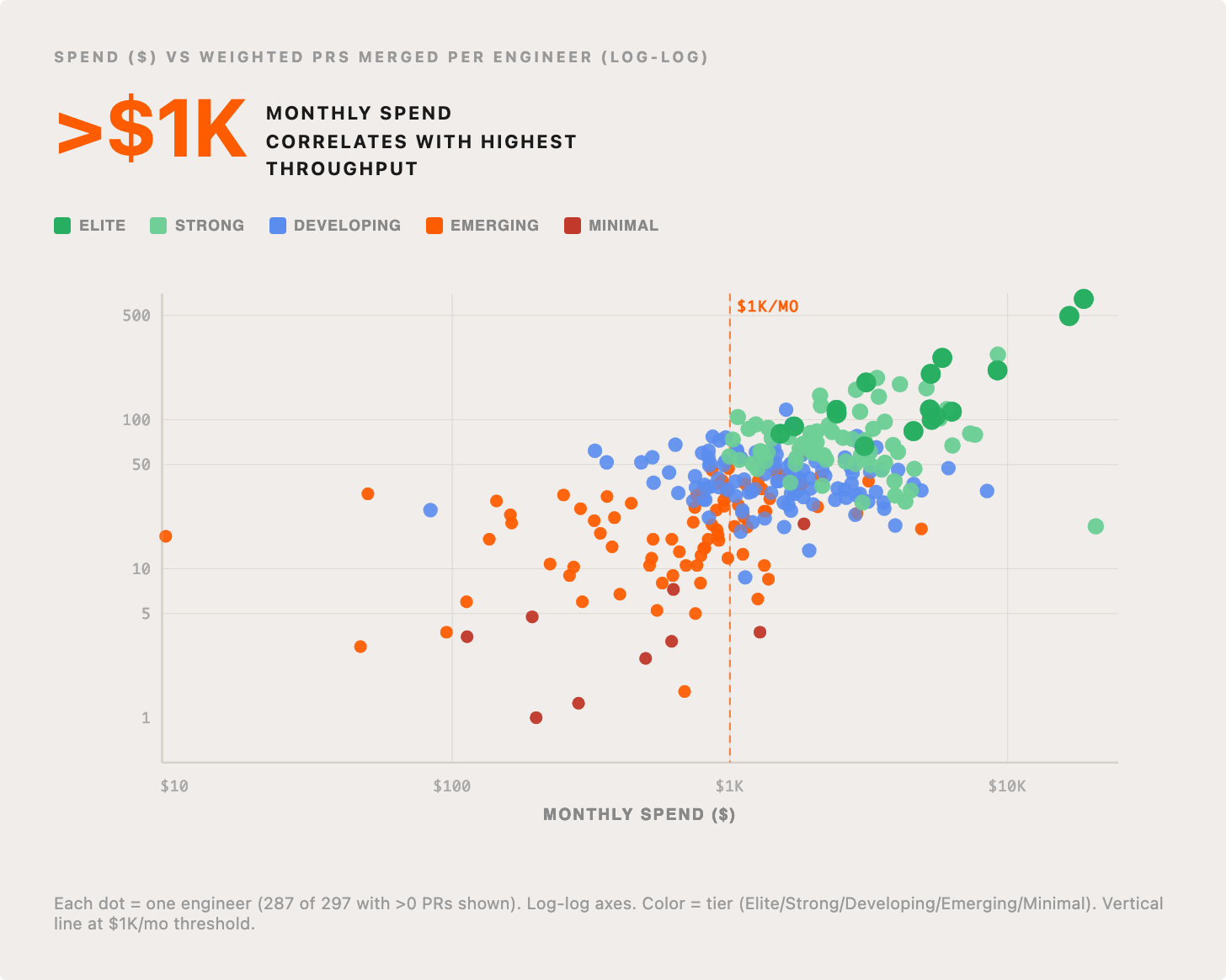
This scatter plot of our engineering team shows that the vast majority of people who are meaningfully pulling up the average are spending >$1k per month on tokens, but spending >$1k doesn’t guarantee that.
It’s ironic that the sentiment amongst many leaders or CFOs is that this is all becoming too expensive, our evidence suggests that it’s way more expensive in the long run to hold back spend, because of the downward pressure AI leverage plays on the fully loaded cost of a PR, which is dominated by salary costs in almost all organizations.

We need to figure out ways to help everyone move up and to the right. We think about this as a progression from minimal, to elite use of agentic tooling. Our top 5% of engineers operating at an elite level produce >6x the output of the median engineer.
The tiering is computed based on an assessment of an individual’s intensity of AI usage, overall output, depth of AI usage, efficiency of AI usage ($/PR), and prompt quality. All our telemetry on these dimensions helps us spot opportunities to better equip or enable the team to make progress. We will share more on this later.
Changes beyond R&D
The impact has been significant within R&D, but also inspiring beyond R&D. I’ll give a glimpse into that here.
Everyone reflexively uses AI now as part of their job, whether that’s Glean, ChatGPT, Claude, Claude Cowork, or in our case, Claude Code. We’ve 473 people in R&D, our peak has been almost 1,100 active Claude Code users across the company (out of total company size of 1,305). That’s over 600 people who got over the temporary intimidation of learning how to use the command line and are now able to create reports in minutes that would have taken them hours, or that they simply couldn’t have done before. Regularly, I bump into people brimming with excitement, from our finance team, or people team, or recruiting team, or customer service team, or sales team, or legal team, who are on a really fun journey of discovery around what they can get done from an AI Agent with access to the right data and tools. Some of this use is one-off analysis, some of it is replacing complex parts of our operations, with specialized skills being built to report and critique monthly performance. And people push this beyond just reporting, building special purpose tools for sellers or even prototypes of potential product capability.
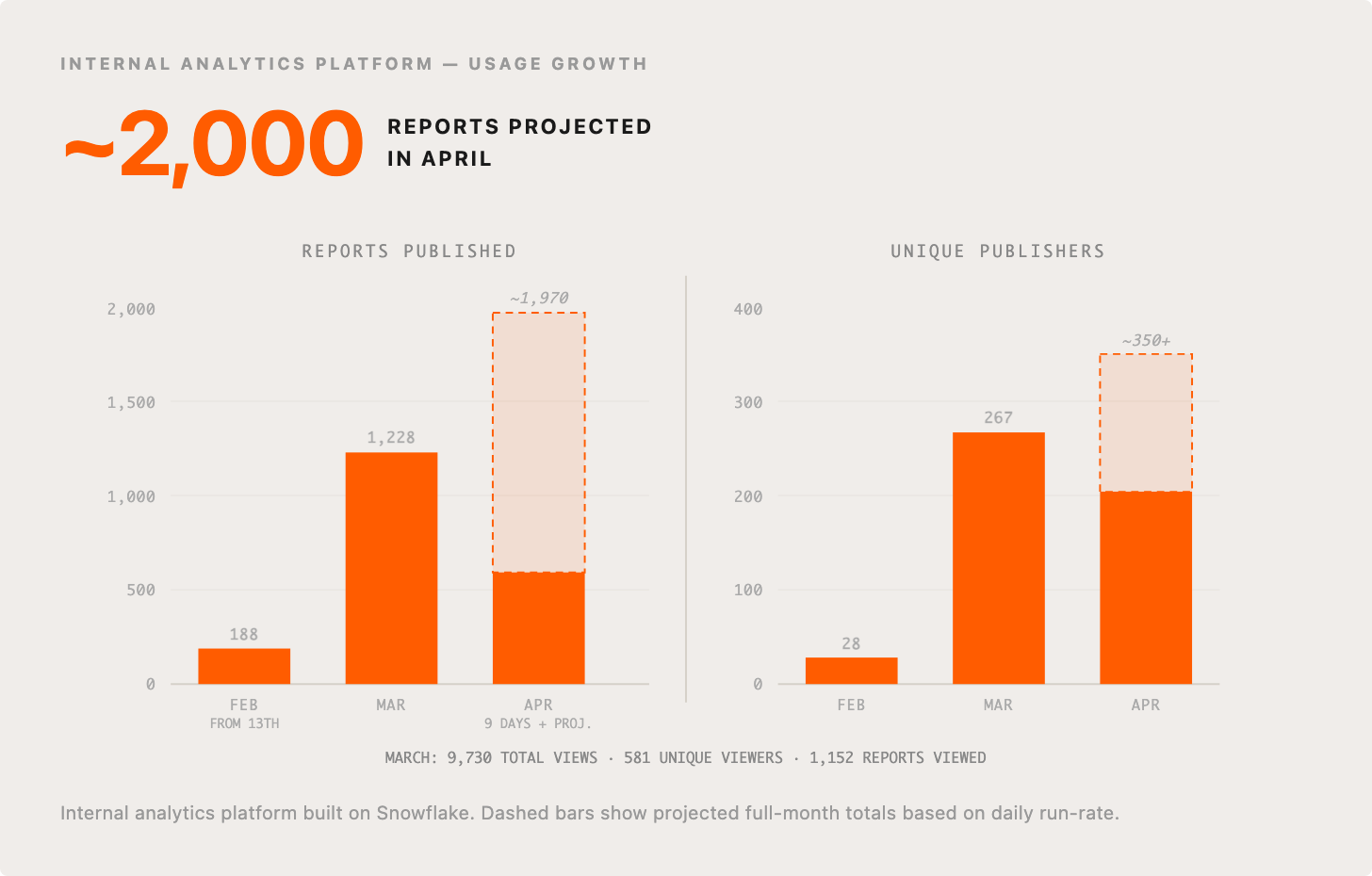
Cormac wrote about how “every business leader deserves their own data analyst,” which totally undersells the impact of the tooling his team have created. For starters, it’s not every business leader, it’s everyone at your company. The tooling allows you to ask any question you want about the data in Snowflake and any other systems or context you are interested in,has skills for creating interactive reports or mini applications, and then publishing them securely with the right access controls, versioning deployed using Streamlit on Snowflake.
Usage has exploded from initial versions of this in February, and no sign of slow down in April so far, stats here for reports actually published to the internal platform for sharing them:
What next…
I hope I’ve shown you the power in picking a target, no matter how imperfect, and pursuing it with great determination, can lead to massive cultural change and impact for your company. I hope that the transparency I’ve afforded helps motivate and inspire you. I hope it gives you benchmarks to try and smash – or if you’ve already done so, I hope you’ll share your receipts too for further inspiration.
Tune back in soon for my next post, where I’ll share all about the messy journey, how we did this, what we’ve learned along the way, and what’s next.
One last thing, I and other leaders at Intercom have been inundated with customers and peers in the industry wanting to pick our brains and draw inspiration for how we are leveraging AI in our teams. So we are going to do a big group webinar, targeted at people leading organizations like ours, where we’ll go into more depth, and have very open and honest Q&A sessions too. Please save the date, May 19th, 9am PT, 5pm GMT, and register your interest here.
Big thanks to Claire Vo for very kindly reviewing a draft of this post at short notice and providing really useful feedback.
Darragh, really appreciate the transparency! Willing to share your story at our next AUTONOMOUS summit end of May? We typically get around 15,000 participants, and this time we're exactly focused on this type of fundamental transformation stories. It would be great to have you!
Curious on how you're measuring token spend. I'd like to do similar graphs with my team's data, but finding the Claude analytics data a bit more miss than hit. FWIW we're on the plan instead of on-demand billing