

The role nobody talks about in forward-deployed AI teams
Forward-deployed engineers configure the AI. Forward-deployed data scientists prove it works.

Data scientist was once the sexiest job in tech. Now it’s the forward-deployed engineer. So naturally, I became both.
In 2012, Harvard Business Review gave data science that famous label. Fourteen years later, the role everyone’s talking about is the FDE. Palantir coined it, OpenAI has just launched a $4 billion deployment company around it, and The Pragmatic Engineer has covered the trend extensively. But there’s a role emerging alongside FDEs that I haven’t seen much written about.
I’m a Forward-Deployed Data Scientist at Fin (formerly Intercom), here’s what that looks like and why I believe it’s one of the most important jobs of the AI era.
The product team parallel
If you’ve worked in a product-led company, you’ll know the classic trio: a product manager, an engineer, and a data person. The PM and engineer build things. The data person helps the team understand what’s worth building, what’s happening in the product, where users are getting stuck, and what to experiment on next.
Without that analytical layer, you’re building on instinct and hoping for the best.
Forward-deployed teams work the same way. At Fin, we operate as small cross-functional units known as “swarms.” Each swarm is dedicated to a single customer engagement: a forward-deployed engineer configures Fin for the customer’s environment, a forward-deployed product manager manages the relationship and workstreams, and the forward-deployed data scientist (FDDS) owns the analytical layer. That means metrics definition, performance measurement, and the commercial story that ties it all together.
The FDE configures the product. The FDDS defines what success looks like and proves whether we got there.
Why the role exists
We’re two years into AI adoption and there’s a lot of conversation right now about whether companies are seeing ROI on their AI spend. You’ve probably heard the recently popularised phrase “tokenmaxxing” by now; companies maxing out AI usage without measuring whether it’s doing anything useful. Uber burned through its entire 2026 AI budget by April, while Amazon employees were spinning up AI agents to complete meaningless tasks just to inflate their usage stats. The backlash is real.
This is the world we work in, except on the other side of the table. Swarm engagements are high stakes, focused on our largest customers who have significant opportunities for automation. These deals can be worth seven figures, with CFOs, CEOs, and founders in the room. Nobody is signing off on that kind of spend because the demo looked good. They want to see that the AI actually works for their business, and delivers measurable value.
The FDDS role exists to do exactly that, and it works in two directions. First, we do the upfront analysis that sets Fin up to succeed: understanding the customer’s conversation mix, scoping what’s automatable, and making sure the engagement is focused on the right things. Second, we do the analysis that proves the value after Fin is live. That means tracking performance, identifying gaps, and building the commercial narrative that justifies the investment.
Without the first part, Fin might be configured for the wrong use cases and underperform. Without the second, even a great deployment won’t get past the exec sign-off. If you can’t show the value, the deal doesn’t close. Both are data problems.
What the work looks like
Understanding the customer’s world before touching the product
Every engagement starts with understanding the customer’s business: what are their goals, what do they care about, and how do we measure success? That shapes every subsequent decision.
We start with a taxonomy analysis. The customer shares a sample of their support conversations and real interactions between their customers and their support team, whether that’s human agents or an existing AI tool.
Our job is to make sense of it. What are the most common things their customers ask about? Which of those are simple and informational (someone looking for a help center article) and which require real complexity?
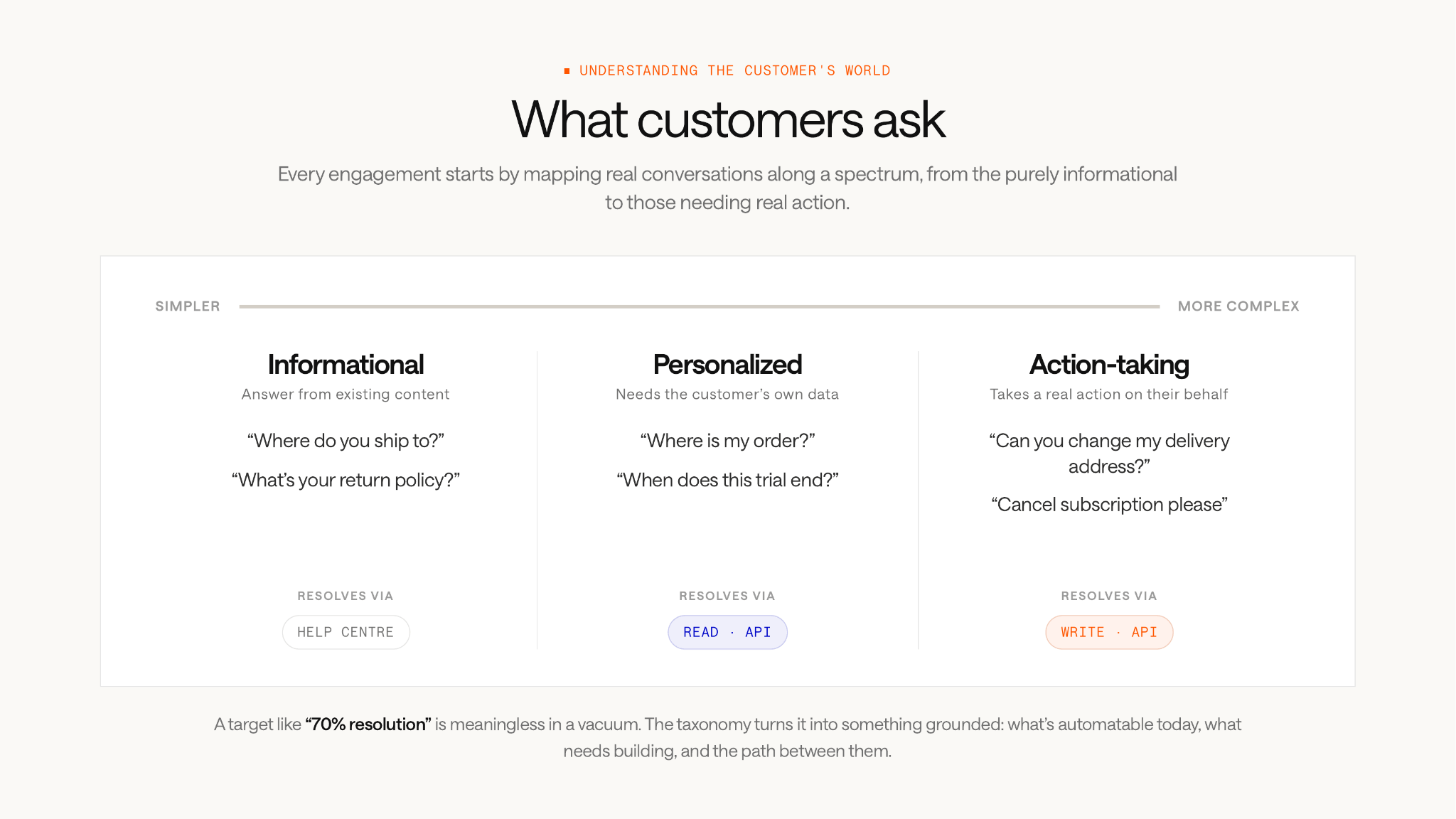
“I want to cancel my subscription” sounds straightforward, but it might require Fin to check what plan the customer is on, look up their billing history, apply a retention policy, and trigger a cancellation through an API. That’s a completely different challenge to “what’s your return policy?”
We break conversations down along a spectrum, from purely informational queries, through to ones requiring personalized data, all the way to those needing real actions on the customer’s behalf. We also map out the read and write operations needed to resolve each type. That gives the engineer a clear picture of what APIs and integrations to build, and it gives the PM a realistic scope for the engagement.
Without this process, targets get set in a vacuum. A customer might aim for 70% resolution rate without realising that a significant chunk of their conversations require API integrations and engineering work that hasn’t been scoped yet. The taxonomy turns an ambiguous target into something grounded: here’s what’s achievable today, here’s what needs to be built, and here’s the path to get there.
If we find that 50% of an ecommerce customer’s inbound volume is about order tracking, that becomes the focus of the proof of concept. There’s no point trying to boil the ocean in a two-week proof of concept. You find the highest-value, most achievable use case and prove it there first.
But the taxonomy doesn’t just define the POC. It also becomes the foundation of the customer’s automation roadmap. We can show them what Fin can resolve today and a clear path to an 80 or 90% automation rate. That roadmap turns a short engagement into a long-term picture of what’s possible.

Tracking performance in production
Once Fin is live, the role shifts to continuous performance analysis.
Resolution rate is often the headline metric: what percentage of conversations Fin handles end-to-end when it has the opportunity to answer. But the number alone doesn’t tell you much. You need to understand why Fin is struggling where it’s struggling. Is it a knowledge gap, like missing content in the help center? A complexity problem, where conversations need actions Fin hasn’t been set up to handle yet? A quality issue, where Fin is responding but customers aren’t satisfied?
We run this analysis throughout the engagement, flagging gaps and working with the team to close them. In one engagement, a taxonomy analysis mid-trial showed Fin was resolving 90%+ of informational queries but struggling with a specific category of action-based requests. That clarity let us focus optimization efforts on exactly the right conversations, and within weeks the overall resolution rate went from around 50% to over 65%.
We also look at quality metrics, recontact rates, and customer satisfaction to make sure we’re not just resolving conversations but resolving them well.
Proving the value
This is the part that sits furthest from traditional data science. The analysis doesn’t end at a dashboard but a contract decision.
At the close of an engagement, we present an evaluation readout: a full picture of what Fin achieved and what it means for the customer’s business. The challenge is that “value” looks different to every customer.
Some are purely focused on resolution performance. Others want a cost savings story, where Fin handled X thousand conversations that would otherwise have needed a human agent, at a saving of Y. One customer aimed to measurably improve retention by authorizing Fin to offer a discount to customers that are trying to cancel. That’s a very different success metric to everything else.
In one instance, we had a customer evaluating Fin alongside a competitor. On the surface, the competitor looked cheaper. But when we dug in, the comparison wasn’t like-for-like. The competitor charged per conversation, whether the AI performed or not. Fin charges per outcome, so you only pay when it completes the action you’ve configured it to execute. Once we built a total cost model that accounted for what the customer was really paying on the competitor’s side, the economics flipped and the customer chose Fin.
This type of analysis would be difficult for the sales team to produce independently. It requires a data scientist with commercial context and a deep understanding of performance metrics to spot discrepancies like these and explain why they matter.
Scaling what starts as bespoke
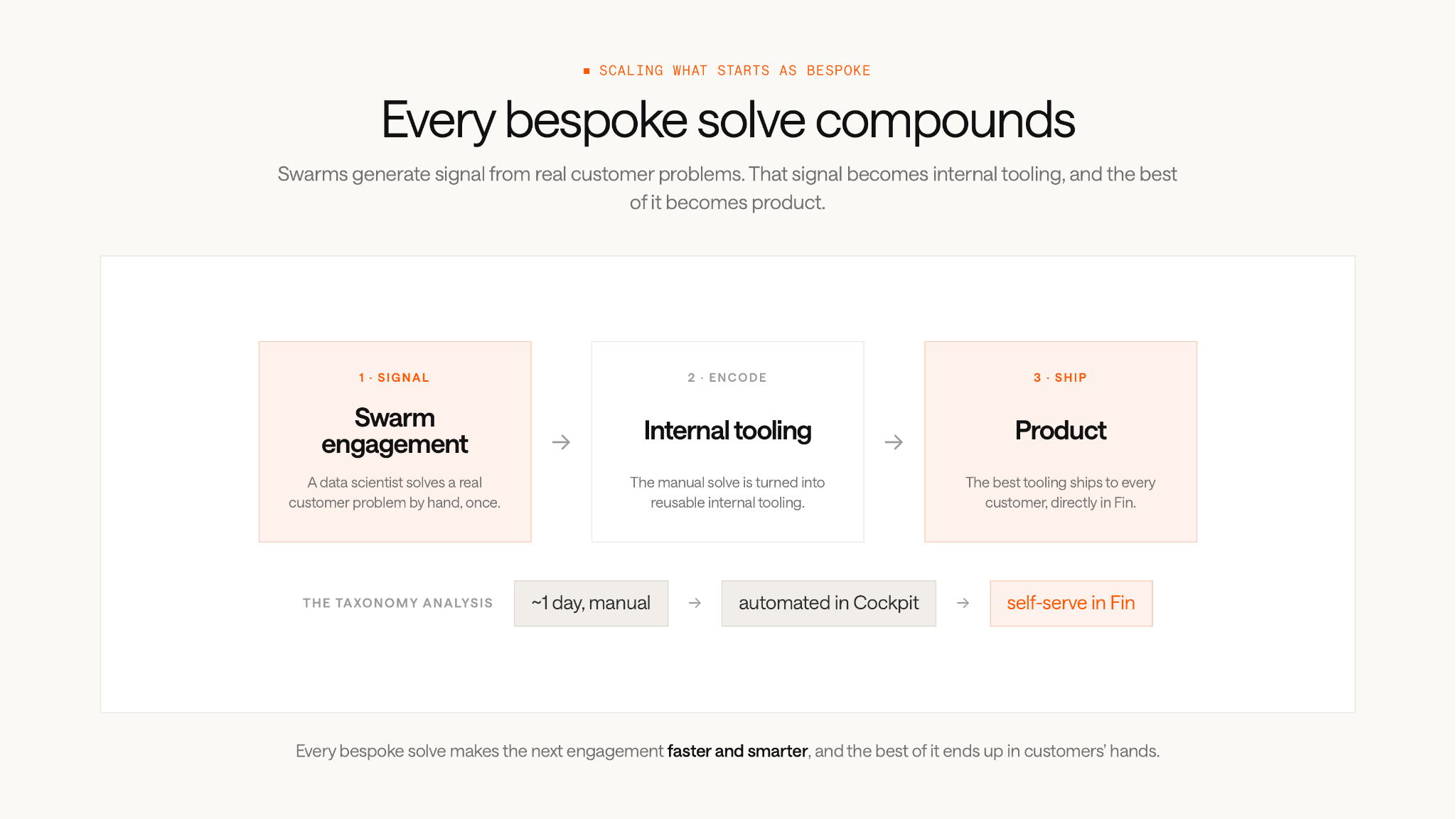
The most valuable thing about forward-deployed work is the patterns you see across customers.
My colleague Kevin O’Brien wrote about this in detail, but the short version is that we operate a loop: swarms generate signal from real customer problems, that signal gets encoded into internal tooling, and the best of that tooling eventually becomes part of the product.
The automation roadmap is a great example. What started as a one-off deliverable for a single engagement is now generated automatically, replacing hours of manual work.
Similarly, we can now easily generate performance decks. A custom-made narrative for one customer became a pipeline that created more than 450 customer-specific decks. It’s changed how our entire sales organization communicates the value of Fin.
Some tooling goes further still. Take the taxonomy analysis. It started as a manual exercise that took the better part of a day. We built it into Cockpit, our internal insights platform, so that any customer-facing team could run the same analysis without needing a data scientist in the room. And today, it’s accessible to customers directly in Fin.
This is how the work of forward-deployed data scientists compounds. Every bespoke solution makes the next engagement faster and smarter – and the best of it ends up in the hands of our customers.
Can we reclaim our title?
Fourteen years ago, Harvard Business Review called data science the sexiest job of the 21st century. Forward-deployed engineers are having their moment now. But deploying AI isn’t the same as proving it worked – and as businesses demand ROI on their deployments, someone needs to own the “did it actually work?” question. That’s a forward-deployed data scientist.
 | A guest post by
|