

Webinar Q&A: How Fin 3x'd R&D output in 16 months
Our answers to your 72 questions
We recently hosted our first 2x webinar, sharing quite transparently how we are approaching R&D acceleration at Fin.
It was very much a live demo that let us walk through some of the key components of our system.
If you missed it, you can watch the recording here.
We loosely committed to answering all questions in some way, so here it is. Feel free to continue the conversation in the comments, or reach out if you have any questions about Fin, Intercom, our AI models, or anything we discussed on the webinar.
Thanks to my colleagues, Brian and Kesha, and to everyone who showed up and asked great questions. Special thanks to our guest, Claire Vo, for joining us and having Brian on her “How I AI” podcast recently.
We hope to do more events like this very soon!
Connect with us here:
Org structure, team, and staffing
What size team works only on the agentic harnesses and how do you handle roles and responsibility? (Asked by AS, similar by EL)
How do you staff development of Fin’s “agentic coding system” (skills, Shrek, agent observability, etc)? How much is dedicated platform team(s) vs. grass roots contributions from product engineers. (Asked by NS)
Currently, a very senior core team of three IC engineers (Principal/Senior Principal), two Senior+ engineers, a Staff TPM, and a VP eng. We’d had a couple of other engineers tour in and out based on opportunity/capacity. They’re pretty autonomous on deciding what to work on. I meet with them weekly to stay close and provide input. This team has existed for about six months now. We wish we’d started sooner, but it always feels very hard to pull some of your best off other critical projects. The payback has been immense though. In addition to the team, it’s explicitly everybody’s job to contribute to the system, help encode context or skills unique to them or their team, and act on feedback loops to drive improvements in the system.
Have you restructured your org to adapt to these new processes? (Asked by YG)
Essentially no, not dramatically. We’ve formed our team-2x, and there are many local experiments with different/leaner team structures, but no dramatic re-orgs. We do, however, intend to push harder in this direction, as often making changes (for example, shrinking teams) forces valuable lessons around what works better, what breaks, how to adapt, etc. – things you can be insulated from in old world structures.
How will roles in engineering change? (Asked by KG)
At a high level, we see many adjacent roles blurring together: your best engineers already have great product judgment, and will take on more of the PM role, creating space for the PM on higher impact work, and reducing coordination overhead internally. Directionally, what is a team today should be a single person on some near-ish timeframe. In that world, engineers need to be well equipped to strongly own areas of the product/system, set great direction, and execute with high levels of independence.
Productivity metrics and impact measurement
How do you measure the actual impact beyond throughput? Does 3x increase in PR correlate to business outcomes and product value that’s relevant for your organization? (Asked by AK)
The real prize is our ability to solve customer problems, and bring our vision to life dramatically faster than before. This shows up for example in our rate of significant product launches, or in our defect backlogs burning down. You should expect revenue to be a lagging indicator; we see revenue growth to continue accelerating.

More directly to your point, it was and still is true that the number of PRs doesn't directly translate into business impact. However, it is a required pre-condition to be able to ship at least something: required, but not sufficient. At this stage, we are heavily investing in ensuring all our operations are streamlined to make sure if we want to ship something, it is agentic-first, fast, safe, with minimal human intervention.
Do your engineers know how you're measuring productivity? How do you prevent them from gaming the system or account for gamification? (Asked by AK)
Claire said this best: gamification is a culture problem, not a measurement problem. That’s the broad strokes answer. We’ve a high trust, high transparency culture with people who care about their work. Having said that, we are all human and the pressure to hit/increase this metric can be a source of stress. When we introduced tools like Buzz, which enable the offloading of work to cloud agents, initial versions didn’t attribute the work to the person who initiated it, and there was reluctance to use this system out of fear the impact wouldn’t be attributed to the person. We fixed the attribution to prevent resistance to using this power tool. Ultimately, anything egregious would become obvious quickly, energy spent trying to game is far better spent trying to win together.
What business metrics have you tracked and noticed changes in as a result of AI-assisted development? I noticed DORA-like metrics earlier – I am interested more in business metrics/OKRs etc. (Asked by SC)
Your metrics showcase eng metrics, what about customer delight or revenue? Were you able to show causal changes? (Asked by AL)
Best ones we have are product release throughput and time from idea to release, tier 0 marketing releases, or our recent Intercom 2 launch. Like I said earlier, revenue growth is accelerating for us. Another example is that we are able to say yes much more frequently, which translates into deals closing that would have been blocked, or accounts churning because we can’t support their evolving needs.

What was the target metric you started with? PR count? (Asked by AL)
Yes, merged PRs, but specifically total merged PRs divided by total number of people in the entire R&D org. This is about measuring the throughput of the entire system, not just the per engineer output. Total throughput has increased further as we’ve been growing our team too.
Have you also started measuring the change in PR size? Or ways to keep PR sizes low/discrete? (Ask by DK)
A: Yes, some details here. TL;DR; size has increased a little alongside volume of PRs. Intuitively, agents great at writing code and tests tend to get more tests as a result. Our AI approval system provides natural incentive to keep PRs small and focused, as they’re more likely to be AI approved, which enables faster flow through the system. Small focused PRs are also inherently safer, so that’s win, win. It’s early days, but we expect this to apply downward pressure on PR sizes.
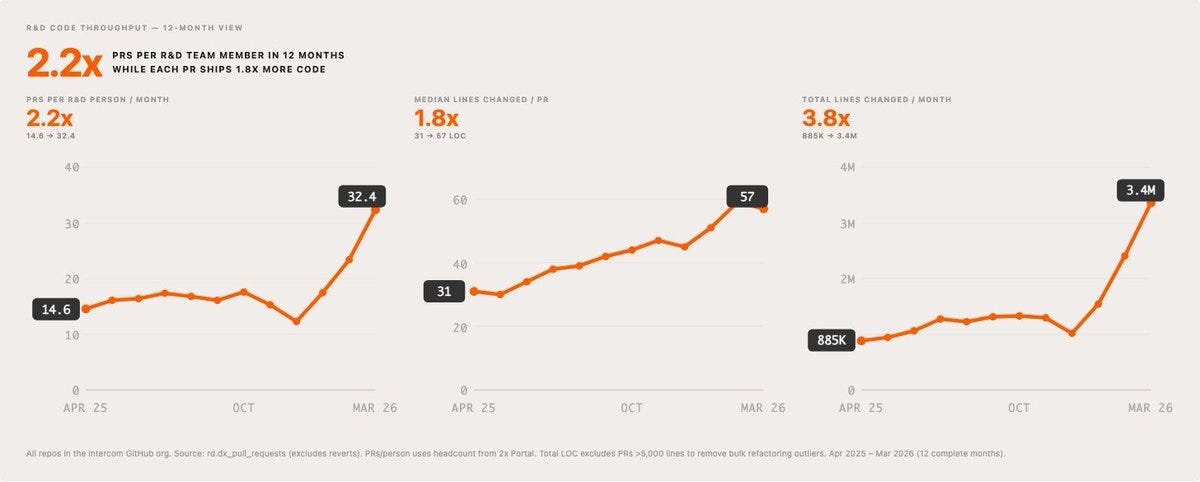
Did the limit of 150 lines cause the increase in PRs per dev? (Asked by RM)
As mentioned above, there is a healthy incentive towards smaller PRs that are more likely to be AI approved and flow through more quickly. Smaller independent changes tend to be safer too.
PR workflow, review fatigue, and auto-approval
In Darragh’s article on X, you mentioned about 20% of your PRs are created and reviewed using AI. How do you maintain cognitive control, and what happens when things go wrong on these fully agent-driven PRs? (Asked by MK)
For human-initiated PRs, authors shouldn’t be blindly shipping and hoping AI allows it through. Engineers still need to have an opinion and take responsibility for the shape of the solution. In addition, our system encodes opinions about how we should solve problems, patterns to follow, etc. Our review system helps enforce this. When things truly go wrong and, for example, we have an incident, we do a deep postmortem and figure out the right corrective measures.
Curious to know how you deal/dealt with PR review fatigue. (Asked by NC)
AI review and approval is a big part of this, as well as humans having a way to encode the perspective they’d typically bring to a review into repeatable instructions/guidance for the review and approval systems.
How do you gate “Eligible for Auto Approval”? (Asked by RG)
Multiple inputs to this: PR size is one heuristic, other signals that indicate the level of risk/blast radius etc. More details here.
Do you have a classification / risk rating for PRs so you can auto-approve lower risk PRs? Do you have different agents running for this? What do your scheduled processes look like? (Asked by GF)
Yes, sub-agents with discrete tasks/responsibilities, all triggered on PR submission. Auto approval focuses most on low risk changes.
If the PR is not auto-approved, what are the next steps that take place in an agentic flow? (Asked by NF)
Today, it passes to the typical human approval flows, with some automation to notify the right people/teams in Slack.
Is everybody allowed to edit the reviewer prompts? (Asked by MB)
Yes, but this requires peer approval. In practice, owners/experts in particular parts of the system own/take responsibility for the review/approval requirements for their area of expertise.
Is it only one reviewer, or have you split it into a few different agents in parallel? (Asked by MB)
Many specialized review agents in parallel, and again, owners/experts in particular parts of the system can guide additional ways that their code is reviewed.
Skills: Creation, distribution, evals, governance
How do you distribute your skills? (Asked by IK)
A hierarchy of Claude Code plugins. Initially, we did that via a private marketplace, relying on Claude Code to auto update. We found the auto update wasn’t as reliable as we’d hoped, so we forced this using our IT MDM systems to ensure everyone has the latest version of master ~ at all times.
What skills and MCPs have you got? (Asked by GF)
LOTS. The intention is that the agent has access to all the tools a human engineer would, and that they work out of the box. Quite a bit of care and attention have gone in to achieve this. Of course, auth is required and some hooks that help make sure you resolve auth issues, rather than the agent deciding to not use the ideal tools available. We organize skills in hierarchy: our base plugin holds skills core to every person’s job, then separate plugins, many disabled by default for things like different languages/frameworks, and team/role/product area specific skills. We have hundreds of skills in total, but we also have processes for gardening and removing skills that don’t get traction, and promoting/improving skills that do.
Are the skills you’ve placed in the plugins actually reusable across multiple projects? How do you avoid them becoming too generic but still usable across several projects? (Asked by EL)
For starters, we’ve largely a monolithic architecture, so lots of general reuse. We don’t really have this problem, but do also leverage, for example, team-specific plugins where the goal isn’t general purpose. If we need to, we can promote skills that end up being generally useful from team to shared plugins.
I love the idea of constructing many small skills designed for individual parts of processes. Did you guys develop a methodology for how skills should slot in with each other? And how do you determine the architecture for how these skills interact as a whole? (Asked by JG)
Basically, not really. Emergent for now, we instrument all skills automatically so that we can spot trends in usage and effectiveness, and investigate how skills interact through session analysis.
How do you decide on narrow skills vs skills with many references, for example, a “query-snowflake” skill with many references for how to query certain table schemas where the skill.md progressively discloses which references to load, vs. individual skill workflows like “gong-call-insights” that tells Claude how to use Snowflake to query? We made a marketplace but are finding it hard to find the balance. (Asked by RC)
Agree there is a bit of exploration to find the balance. In this specific example, we’ve gotten a lot of general purpose utility by giving Claude select star and Snowflake access and that being enough to serve open ended analysis. However, it runs the risk of being good enough to be dangerous by creating a bunch of impressive but incorrect output. So alongside this, there are layers of guidance or skills that put guardrails or manners on how it will do certain things, make sure it understands some of the nuance of how data is captured, how to accurately report on ARR, for example, or more specific, like your example, task specific skills like analysing Gong calls.
How do you direct the agent to preload skills? Or does that just happen? (Asked by RC)
We use Claude Code and it puts a system reminder about every available skill into the system prompt. Unfortunately, that’s unreliable, so we use deterministic Claude Code hooks (regular scripts) that inject the context into the session based on certain conditions. For example, we have create-pr skill and we really want Claude to use it every time it creates a PR. To ensure that, we monitor Claude attempts to create a PR using gh tool, intercept it with a hook, and, if create-pr skill wasn’t loaded in the session yet, inject a prompt for Claude to load that skill.
Do you have evals that you run against the skills? How have you curated examples and set that up if so? (Asked by MK)
We have a set of evals in the same repository along with the skills. Basically like automated tests. As skills are used and new edge-cases come up, we habitually update evals with more test cases. For our PR review agent, Shrek, we do batch evaluations – we have a human-curated set of historical PRs with confirmed issues. Any time we change the agent or the prompts, we re-run evals to confirm its performance (alignment with ground truth) hasn’t degraded. Building and curating a dataset is by far the hardest and most time consuming part. As we are not experts in every repository we have to engage with experts in corresponding areas and create incentives for them to invest their time. Spending less time on reviewing PRs manually is a good incentive for them to contribute.
What’s your skill governance workflow? How are they authored, validated, reviewed? The same as code? (Asked by SS)
Yes, same as code. Then rules for how/when skills get promoted higher up the hierarchy. For example, 50 weekly active for a skill to be eligible to promote to a base plugin.
How do you avoid context explosion with so many skills? (Asked by MR)
Splitting into the hierarchy, and most plugins disabled by default, for example, team specific ones.
Agents and Shrek: Infrastructure
Can you elaborate a bit more on the infrastructure behind Shrek? Where is it running and what are the guardrails instrumented on the runtime platform? (Asked by LdAS)
Shrek is running on AWS infrastructure in isolated, short-lived containers, triggered by GitHub webhooks. Each container has read access to the codebase and the code changes diff, as well model providers’ API access (it uses both Claude and Codex). Shrek reviews are guardrailed using strict safety criteria per code repository that define what areas of the code are safe to auto-approve (if the review verdict is positive) or require an engineer in the loop.
What is Shrek built on? Is this home-rolled based just on a model, or based on something else? (Asked by IK)
Shrek is a Python app built on top of Claude SDK and the Codex APIs, with custom prompts and curated evaluation criteria for every type of review it needs to do (from basic things like PR descriptions, to company and team-specific code review and safety rules, to general logic bug finding investigations).
Which tools do you use to construct Shrek? (Asked by VD)
As above, in conjunction with a custom framework to run statistical analysis of the impact that individual prompts (and changes to those prompts) have on correctly judging a code change. Engineers use the framework to curate a dataset of PRs of various types with expected review outcomes and the framework runs simulated tests, producing statistical significance results on whether the prompt changes move the needle in terms of recall and precision.
To what extent do you use cloud environments where an engineer can start working immediately? (Asked by NG)
Engineers work on local development environments, but we invest a lot to make those work seamlessly/smoothly, have agents to help resolve issues, have the dev env in CI to automatically catch regressions, etc.
Do you have a unified solution for agent observability? How much of the agent evaluation and observability stack is in-house? Can you recommend a solution that a small company can easily adopt? (Asked by NG)
Yes, some hooks into Claude Code platform (part of what we like about Claude Code here is the extensibility,) and OTEL outputs into honeycomb.
Do you have autonomous agents that propose pull requests or any sort of changes without being explicitly asked (e.g. triggered via cron schedule, Claude routine)? (Asked by NG)
Yes, for example, our Buzz system can be triggered on schedule or by webhook.
How do you store product requirements / intents that are typically not captured in the codebase, so they can be accessed by agents? (Asked by NG)
Our agents can access docs just like humans and sometimes that’s the answer here, but there is also some discipline around capturing important context like this in the codebase documentation, and in git history.
Are you keeping your SDLC flows autonomous by creating tools/apps where engineers just interact to provide agency, or is it done in remote setups with all skills shared across the org? (Asked by AM)
A combination of local developer environments and cloud agents, skills are shared across the org (via plugin system, auto updating.) Shared skills was one of the big unlocks for us, gains compound vs. hide in silos.
Tool and model choice
Do you limit tooling? E.g. only Claude or only GPT models? If so, why or why not? (Asked by AVH)
We used to be open here, and permit every engineer/team to choose their own tools, but then got opinionated and doubled down on a single primary tool (Claude Code), which helped ensure gains compounded across the whole team, and we weren’t wasting effort trying to solve for multi-system compatibility with our skills/guidance, which can pull you to lowest common denominator and/or give you inconsistent impact across tools. So Claude Code, with bias towards Opus, and then Codex in some of our autonomous parts of the system (e.g. approval/review).
Do you only use Claude Code directly or also use non-Anthropic models? Anyone also use other tools like Cursor? Do you have Bedrock-flavour hosted models with guardrails from AWS? (Asked by SS)
We mostly use Claude Code models. We use OPEX GPT models a bit in our autonomous systems. We’re exploring Bedrock-hosted models primarily for availability reasons. Some people use Cursor, or historically did, but most of that has shifted to just vanilla vs code now. Increasingly, people aren’t in their IDEs nearly as much, if at all.
Are you migrating to GPT Codex, or introducing it in parallel to Claude? (Asked by RS)
We’re introducing it in parallel to Claude and concretely right now in our review and approval systems.
Aren’t you worried to be locked into Claude Code? (Asked by NF)
Not really worried about lock in. We love the trajectory Claude Code is on, but we also expect that other tools and systems will converge to support the platform surface area that Claude has exposed.
Are you using Cloud Agent / Dev Agents, and does the 3x number include those PRs? (Asked by KF)
We’ve started ramping up our use of cloud agents, and while it’s a small contribution right now to those PR numbers, I expect it to increase significantly as people, for example, schedule or trigger agents on queues of work.
4.6 – is that for cost? (Asked by IK)
While we don’t have any token budgets or hard restrictions on models we are constantly experimenting with different models. Cost-effectiveness is a hot topic at the moment as our usage continues to grow. Some tasks don’t require the most intelligent model assuming the prompts are in good shape. Moreover, switching to a newer model doesn’t guarantee better results. Prompts are tuned to a specific version and even switching within the same family (Opus 4.6 → Opus 4.7) might result in a degradation. We learnt this lesson while building Fin – when you ruthlessly optimize for quality it takes a lot of prompt-engineering to update the model, and it’s often the case that newer models are worse for specific tasks. With Fin, we see far more of the gains come from the architecture and system around the models, than model version changes themselves.
Security, PII, and compliance
How did you navigate DPIA or workplace monitoring laws for the prompt monitoring (as seen in the “How I AI” podcast)? (Asked by RM)
People can opt-out from session transcripts on a per-session or permanent basis, and we pseudo-anonymize session transcripts. Data collection is restricted to Claude Code, and we are not collecting personal Claude Chat sessions. All session data collected is stored in AWS with least-privilege access controls applied.
Do you conform to ISO27001 or ISO9001? How does that affect the agentic workflows and guardrails? (Asked by RM)
How does allowing an agent to approve a PR affect SOC2 compliance? (Asked by PB)
We are compliant with SOC 2, HIPAA, ISO 27001, ISO 42001, and many more. Specifically with our PR review agent, we engaged with auditors long before we even had the agent in place to ensure we have a path forward agreed. Our very first iteration was an agent based on deterministic rules approving changes to documentation/tests/etc – low risk changes. You can read more in this blog post.

Do you have to deal with PII issues when giving Claude access to certain systems, like Datadog, or have you gone through the obfuscation process everywhere? (Asked by IK)
Yes. We are lucky in a way as we already have mutual agreements with all major labs in place since we are using their LLM models inside Fin and trusting them to handle our most precious data: customer and end-user data. This enables us to feed telemetry (logs/metrics/traces) into the Claude session.
Do you have a policy for developers on what they can grant Claude access to? And do you audit that to prevent unintended access? (Asked by IK)
Yes. We have strict controls over allowed Claude marketplaces, MCPs, plugins, shell tooling, etc. There’s a massive attack vector inherent to this new developing area and we treat it accordingly. At the same time we aim for Claude to be able to do/access anything an engineer would. For example, we expose read-only access to our production infrastructure, data warehouse, etc., honoring a given engineer’s existing roles and permissions.
How are you managing access and provisioning tokens for devs and their agents? (Asked by AC)
All engineers/employees have access to Claude Code & Cowork, so far unlimited tokens.
What kind of anonymization do you do on sessions for the session analysis? (Asked by RC)
We have a best-effort obfuscation in place but of course it can’t fully anonymize the session – stripping all the data out if it would render it useless for quality analysis. We are transparent about sessions being stored (with opt-out available) and we treat sessions data in the same way we treat our customers data – there could be some PII in sessions afterall (e.g. logs). For example, we expire session data after 14 days to ensure we are compliant with GDPR data deletion requirements.
Observability, telemetry, and evals
What does your telemetry setup look like? How much visibility do you have into which skills and plugins are being used? How effective they are? (Asked by CT)
We started with the out-of-the-box OTEL monitoring that is built into Claude Code. We use Honeycomb for collecting telemetry, and starting instrumenting other flows as needed. We track telemetry events for every Claude Code Hook event, and we have significant instrumentation for SessionStart that gives us insights into any Claude Code or Plugin misconfiguration.
Have you experienced model drift, and how do you manage that? What about updates to system prompts? Do you execute a similar level of eval to any changes as you do with model changes? (Asked by GF)
We have a range of agents/prompts/skills with different levels of eval discipline depending on the use-case criticality. So far we haven’t experienced model drift in our internal dev tooling. For high-stakes agents like Shrek, virtually any change goes through evals first: changes to the agent code, system prompts, repo-specific code review skills, safety criteria, etc. We treat any change as a hypothesis that needs validation.
SDLC, codebases, and refactoring
Tell us about your SDLC? Are eng moving up front to problem discovery/framing/speccing to lessen the coordination need with PM? (Asked by AL)
Yes! We see that general trend. PM/Design incredibly focused on higher ambiguity and closer to customer and GTM.
Where does refactoring fit in? “Make the change easy, then make the easy change.” (Asked by GC)
Part of the system is encoding preferred patterns/architecture, so low level refactoring can be achieved that way. Higher level system refactoring guided by an engineer (typically in response to running into some limitation that we need to evolve our design around).
Multi-part: (1) How are you making your codebases AI-readable, especially at your scale of millions of lines across Ruby, TS etc.— have you seen the limitations of grep yet? (2) Have you found particular codebases have been harder to bridge to being agentic-first development? (3) How have you been measuring whether a codebase change actually improves agent accuracy? (Asked by OT)
(1) Honestly, not doing much here, some in directory overview documentation, some top level repo documentation to help explain how things are laid out. (2) Yes, a good example of this has been seeing agents/models far more effective writing high quality react code vs ember code. (3) Using a system of evals.
Do you have a monorepo / multiple applications which all share structure so that skills translate across projects? (Asked by RM)
We have a small number of very large repos - e.g. our rails app, a front end application repo, a python repo where much of our machine learning lives etc. We also have a general philosophy of making boring technology decisions, so there is a lot of consistency across all our code bases. So much of the skills that are focused on those primary repos become useful beyond, e.g. we have other rails apps, react apps.
Cost, token spend, and ROI
Were you able to get to an ROI calculation per agent (tokens + cloud costs vs. value)? (Asked by AC)
Yes, kind of. So far, we look at fully loaded cost per PR, and as token spend goes up, and PR throughput follows, fully loaded cost drops dramatically.
How do you manage spend of your tokens across the org? Did you consider leveraging open source tooling? (Asked by AK)
Right now we monitor, but don’t limit. As spend has ramped up we spot systematic improvements that yield cost savings. For example, we realized playwright was defaulting to screenshots that were needlessly high resolution, incurring unnecessary token usage, optimising this saved a projected $300k annual costs without any loss in performance. We aren’t using any specific open source tool here.
How much of developer AI spend ends up being spent on AI skill development? (Asked by RG)
We would have to check more deeply, but by ~PR count it’s ~5%.
API usage billing here – what about the bundled team costs or the enterprise plans? Huge discounts there. Not material? (Asked by IK)
At our scale, API based billing was the only path available to us, some discounts at scale, but not massive. Costs definitely require oversight in the medium term.
Roles, juniors, design, and cognitive load
How do you see the effectiveness of different seniorities when using AI tools? How are juniors growing now that there’s a push to outsource all coding to Claude? (Asked by AK)
The general trend is that some of our highest judgement most experienced people are seeing the highest leverage, however some junior people bring wonderful levels of curiosity, and hunger to learn, and near unbounded levels of energy, and much less hard wiring to the old way and are really thriving. I think we’ll bias towards AI-pilled people with experience who can likely own discrete areas of the product/system, but I’m rooting for the juniors too.
How has this transition affected design? Has design Xx’d output also? (Asked by DB)
Yes, designers are shipping, designers are contributing to the system, mindset of a designer, and generalisable to everyone, is for the things I do, that are often repetitious - is there a way I can encode that into the system so that it can be automated, and similar thinking for places where historically work would block on their input. Trend is they work on higher ambiguity work, and are perhaps pulled in async on other things. Easier/faster to build real prototypes/explore multiple directions in parallel. Now it is expected that designers can/do fix papercuts or small bugs, rather than cut issues, or badger their engineer peers to do it.
Have you found any issues with cognitive debt as Addy Osmani defined it: comprehension debt is the growing gap between how much code exists in your system and how much of it any human being genuinely understands. When we wrote code by hand we would find we couldn’t remember writing it 3 months later; now with AI writing the code we really don’t form a lot of memory about the code and over time have a widening gap of our understanding of the codebase. (Asked by RC)
We think about it conceptually, but haven’t seen major evidence of it being a problem for us. One counter balance to it being hard to keep up with all the change, is that it’s easier than ever to absorb unfamiliar context just in time, and our systems also encourage richer context being captured in our code base and in our git history that adds richness to the context that’s available at our fingertips.
Are you struggling with way more context switching? (Multiple projects/things to think deeply about, etc.) If not, how? We are. 😂 (Asked by L M-C)
Yes! We are all managers now, multi-tasking is often the default, it can be exhausting, we need to still be deliberate at taking focus time for deeper thought. AI does buy more time for us, frees us up from so much of the toil - our approach is that directionally that our agents should be able to do all aspects of the job a senior engineer does, and most obvious places to start are taking the least interesting work off our plates so we can focus our precious brain cycles on the hardest/highest leverage ones.
Culture, training, mindset, and cautionary tales
You mentioned about “pulling up the floor” so that all your staff embrace AI into their BAU. What cultural, training and awareness practices have you implemented (that are beginning to show returns) that have staff both engage and utilise AI – especially staff outside of the classic technical dev roles? (Asked by BMcA)
Couple of things. Early on we wanted to make sure everyone was having a real ‘aha’ moment with respect to how powerful AI tools, for us specifically Claude Code, can be. We had an internal competitive hackathon where people aimed to build a very simplified version of Fin, and compete against some secret LLM judges for the highest performance. Everyone, no matter what their role, had to participate. It got us all tackling problems harder than most of us would have believed we could tackle in a very compressed time window, and exposed us all to how powerful the tools are. At a lower level, yes, plenty of training, plenty of show and tell, people who’ve done interesting stuff demo’ing or documenting it, to inspire others, things like no-IDE weeks, to bootstrap people into an agent first mindset.
What about your situation before you engaged in this effort — systems, processes, people – was crucial to enabling it? (Asked by CS)
Culture that was focused on shipping, and systems/processes optimized around that (e.g. CI/CD).
How hard was it to let code quality slide at the beginning and what was the mindset you needed to have there? I guess that’s the scariest thing for teams that are high performing with high quality bars. Was there any time you weren’t sure you were on the right path? And what was the turning point? (Asked by SA)
Honestly, our take at the time was that much of the measurable drop in quality was acceptable as it was often within reasonable encapsulation boundaries - i.e. a class that’s internally a little messier or more verbose than we might like, or tests that are less precise/targeted than we’d like, but overall working as intended. We also believed in the eventual exit velocity, that as we improved the guidance and context to our agents we could steer them towards higher levels of quality and adherence to our preferred approaches, and that in doing so we could also target and improve legacy areas of lower quality in scalable and autonomous ways.
What’s the biggest mistake / cautionary tale that we should avoid? 🙂 (Asked by DW)
Dragging our heels, not pushing hard enough, being slow to invest in a team to own the holistic system, being slow to pick an opinionated approach, being slow to make it clear how our jobs are/need to change, and the evolving expectations on us all, under forecasting token spend (even though we all thought we were adding generous padding) and now dealing with all the reactive financial planning work.
Tell us about a failure of applying AI in your organization. What did you learn? (Asked by AK)
I think resolving open-ended investigations such as in incident response quickly and accurately is still WIP for us. More often than not, even with a good deal of context about our environment, our agents still confidently identify plausible suggestions that are red herrings. More work to do here! More meta but when we started the effort, our approach was to be maximally permissive, supporting everybody to try any/all tooling. We weren’t opinionated enough early enough, there were gains but mostly in isolation, individuals figuring out personal leverage but rarely compounding across the whole team. It took us too long to centralize on a platform. after choosing claude code, it became immediately obvious that the impact was in improving that platform, and seeing every gain automatically compound across the whole organization.
What are the 1 or 2 things that teams should focus on to get 80% of the value? Fin has a massive R&D team so I am curious about how smaller companies can learn from you. (Asked by MK)
Decide what you want to see, measure it, dedicate appropriate capacity to it, approach it systematically, smaller teams, or teams starting now likely have better off the shelf options for some parts of the system, tools are improving at a rapid rate, so maybe especially for smaller teams they can catch up quickly.
You must have had some scary stuff or near misses happen during the adoption and learning process — tell us! (Asked by SS)
Danny tweeted about this war-story, our biggest WTF so far was when an agent got quite confused, and ended up pushing hundreds of thousands of changes to our Rails monolith, which initially slowed CI down substantially, which escalated to completely breaking our ability to use the repo at all. The good folks at Github ended up having to do surgery on our repo so that we could get back shipping. Agents really will try anything to work around blockers, and sometimes get things terribly wrong.

Another type of nearmiss is in how easily Claude Code will innocently exfiltrate internal info - we realised this early and locked it down - e.g. private gists with problem spec md files - you need to understand and support the kind of workflows your team needs and make sure the path of least resistance isn’t a bad path.
Beyond engineering: Bottlenecks and other teams
Can you also share details how the Sales, CS, and Marketing teams are utilizing AI? Are they using the same infra you built? Do they serve themselves? (Asked by AC)
We built something called “Claude4Data,” built on same CC system, more non-engineers than engineers active Claude Code users. Expanding approach to Claude for sales, general approach is role specific skills and agents that share same data/tool access as human team members, skills that automate common tasks for that team. Also similar to R&D building our the general systems around these teams, e.g. automatic review/feedback on customer interactions, just in time enablement etc. Expect us to share more in the year ahead.
When R&D output 3x’s, the bottleneck tends to move – generally out of engineering and into decision-making, PM throughput, or the narrative layer for the rest of the business. Where did it land for you, and what did the communication design have to become to absorb and benefit from this 3x increase? (Asked by IG)
Claire answered this excellently. Check out what she had to say in the recording.
What’s next?
Why isn’t this a product yet? 😉 (Asked by CS)
It would be a fun one to productize, but we’ve got to focus! I expect there are / will be great products in this space and that e.g. Claude Code is already eating into some of the areas we had to build (e.g. session analysis like Brian talked about). I would add a cautionary note here that the things we are doing are a direct continuation of the culture we’ve been building for over a decade, it’s hard to productize culture, and some of these systems will be very opinionated/over-fitted to our culture. Even with off the shelf tools, you need a very strong internal push, business goals alignment, and willingness to take risks to make progress here.
That’s it! Thanks for reading this far. Thanks for all the questions, and your time/attention on the webinar. If there’s demand we’ll likely do more of these. Always happy to talk 1-1 with our customers who are looking for advice or insight into how to do similar things within their organizations.