

The age of vertical models is here
Last week we quietly shipped the most significant new technology in the customer service agent category since we started it three years ago. It’s a brand new model for Fin trained by our AI Group called Apex, and it’s objectively the highest performing, fastest, and cheapest model for customer service. It beats the very best models in the industry including GPT-5.4 and Opus 4.5.
In this post, I’ll share the news of this launch, the implications it will have for our category, but most importantly, I think, the implications this has for the frontier labs landscape.
The news
Fin was already the highest performing and most sophisticated agent in the customer service space, consistently beating our impressive competitors like Decagon, Sierra and more at an average win rate in the 70s. It operates at tremendous scale, now resolving almost 2M customer issues per week, a number that’s growing at an exponential clip. In its short life it’s grown to nearly $100M in recurring revenue.
As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year we started replacing the off-the-shelf models with our own, custom trained on our proprietary data. But the core answering model was always a frontier labs offering—initially versions of GPT and recently Sonnet 4.0. But now that core answering model is Apex 1.0.
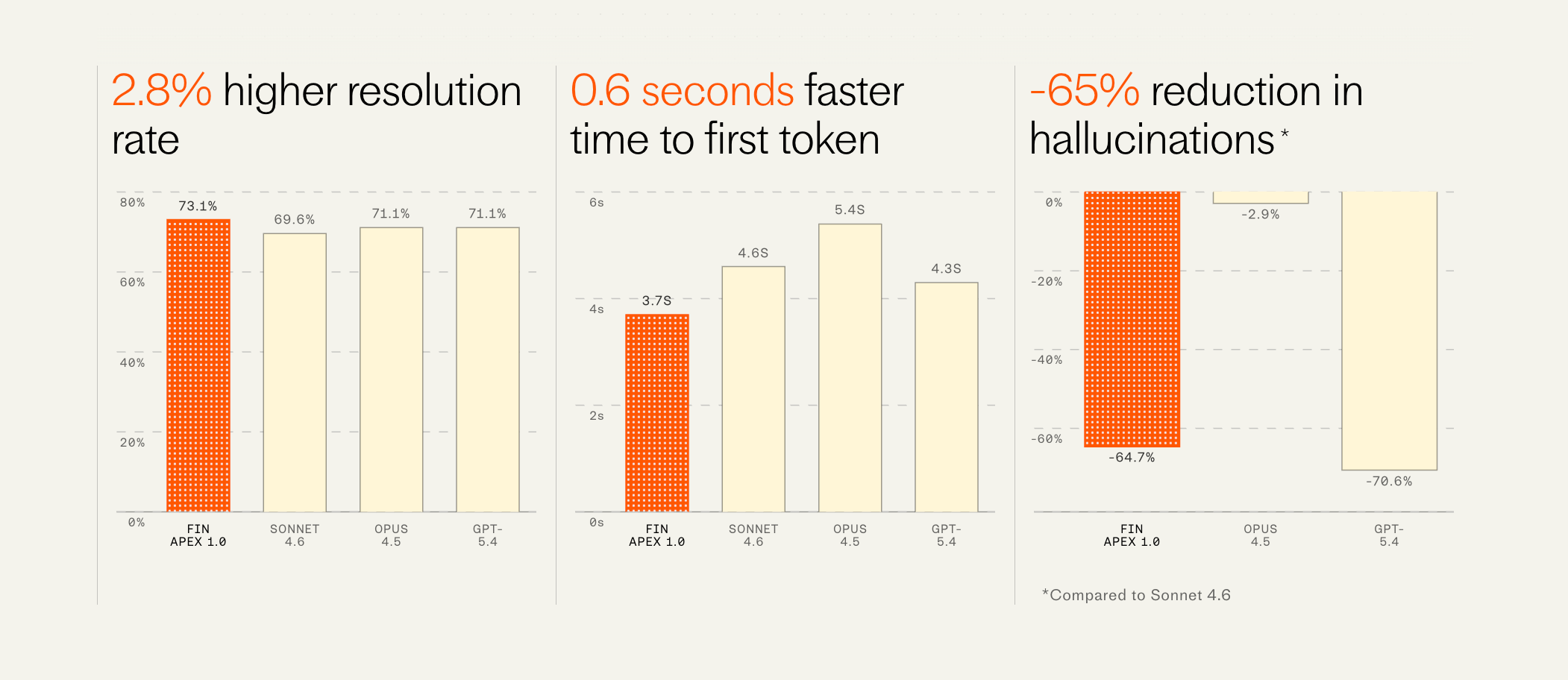
This model resolves customer issues at a materially higher rate than any other model available. One of our largest customers in the gaming space saw their resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). We’ve never seen a jump this large from a single improvement since we started Fin.
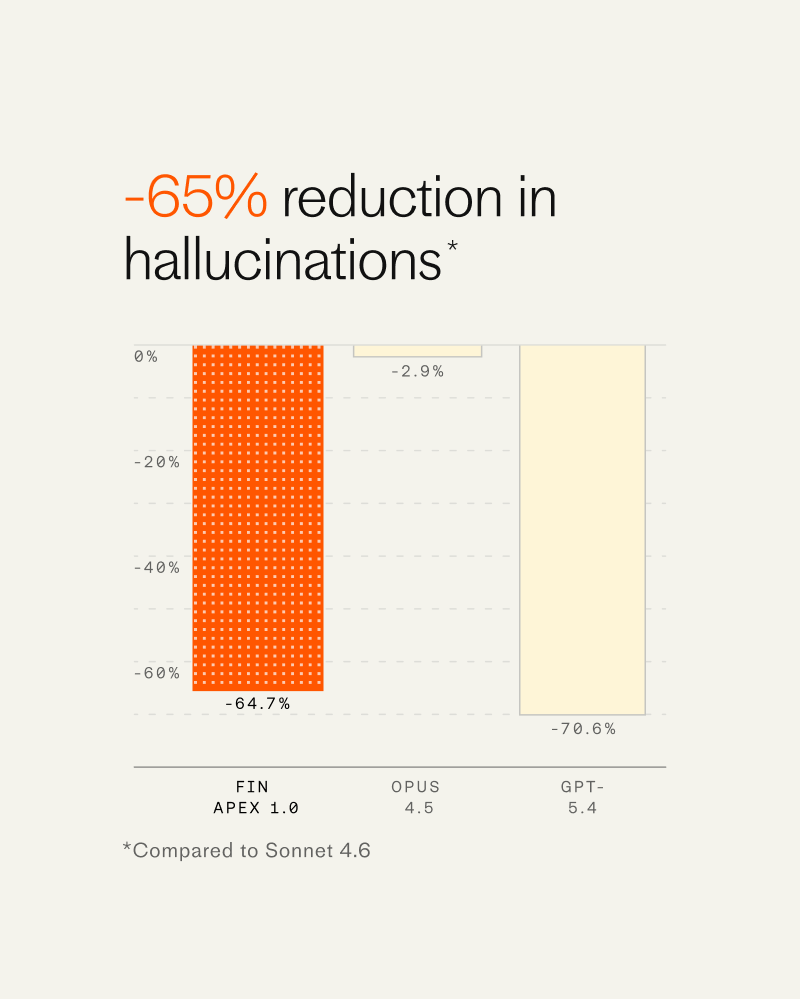
But importantly it’s also dramatically faster, has fewer hallucinations, and is far cheaper than all other available models—all factors that weigh significantly in the consideration of companies deploying these agents to their service operations.
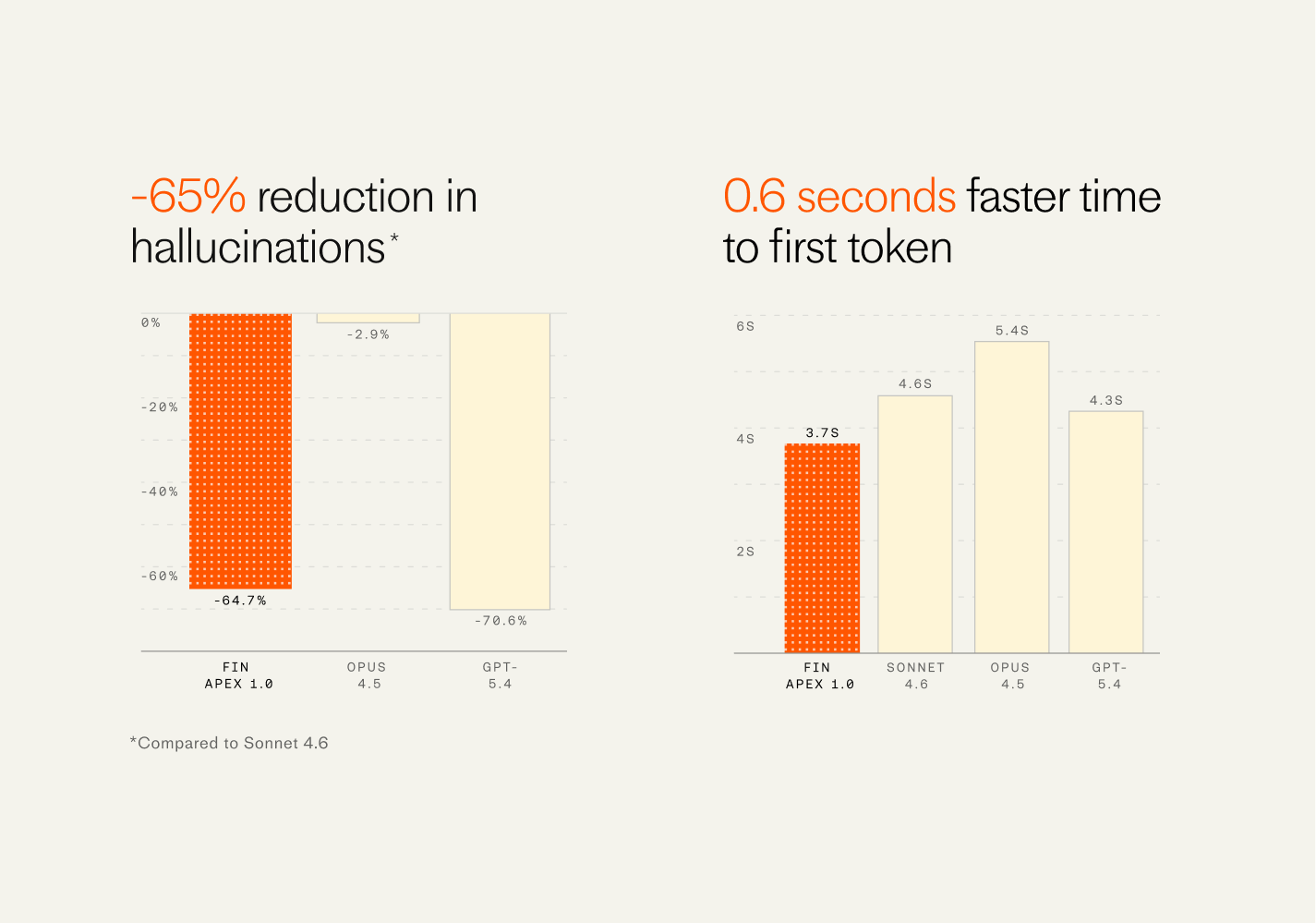
This is an extraordinarily difficult thing to achieve. And we owe this breakthrough to the foundational research coming out of our 60-person AI group run by Fergal Reid. But even for elite teams like his, this cannot be replicated without the domain specific proprietary evals that comprise our billions of human and agent customer service interaction data points created by our Fin resolution engine, which had already been hand tuned to be the most effective in the category. Training with this system makes our setup a flywheel whereby we can continue to train new models that improve at the edge of our system’s abilities. Put another way, I expect that the results we’re enjoying with Apex 1.0 are just the tip of the iceberg.
What this means for the customer service agent category
Service is arguably one of only two or three categories where generative AI has thus far had a material commercial, economic, real world impact. The other being coding, and perhaps the other being the legal industry. The TAM in each of these spaces is insanely large ($250B-$1T?) and as a result they are hotly contested by multiple companies, which have been aggressively capitalized.
We believe that the winners in such spaces must and will become full stack AI companies. And we’ve already seen this just last week with Cursor making the first such move, with Fin being the second. As features become ~free to build, the technology factors that will differentiate the players will be the AI under the hood, and if you’re using the same general purpose off-the-shelf model as everyone else, you have no durable differentiation.
This means that our competitors will indeed need to eventually release their own models. But we see them just starting now to hire for the talent required to do this and so we think we likely have at least a year head start on the space.
Interestingly, 2-3 years ago, this is not how I imagined AI applications would play out. I thought that the points of differentiation would be all of the things we built around the third party models. The AI game will humble you and no doubt make at least some of my predictions in this post eventually look dumb too.
What this means for the AI industry at large
In a podcast interview last week, Andrej Karpathy said:
I do think we should expect more speciation in the intelligences. The animal kingdom is extremely [diverse] in the brains that exist. And there’s lots of different niches of nature… And I think we should be able to see more speciation. And you don’t need this oracle that knows everything. You kind of speciate it. And then you put it on a specific task. And we should be seeing some of that because you should be able to have much smaller models that still have the cognitive core.
The frontier labs still have the very best models, but the open-weight models are not that far behind. So it’s not hard to see pre-training as a commodity of sorts. Where we think the frontier will move next is to post-training. And Karpathy’s prediction is exactly what we’re seeing with Apex (and Cursor’s Composer 2) and what we’re going to see significantly going forward.
As such, the labs are in an interesting position where on one hand the horizontal, general purpose models are actually over-serving the market for specific use cases. E.g. their models are more generally intelligent than is needed for customer service. And on the other hand, the open-weight models are more than good enough where high quality domain specific post-training can make the resulting models superior at the special purpose jobs, and in the ways that matter to that particular job. E.g. in service, the soft factors really matter, like judgement, pleasantness, attentiveness (as well as the hard factors mentioned prior, like the ability to effectively resolve problems, quickly and cheaply).
Personally, I’m still very bullish on the labs. And we remain very heavy customers of Anthropic, whether as part of the broader system of models used for the Fin Engine, or with the depth of our usage of Claude Code in our engineering org. Yet classic disruption (a la the late, great Clay Christensen) is now at their door. The only way out is to disrupt themselves by building cheaper specialized models too. And the only way to do that is to acquire the evals (or the companies with the evals) needed for that specific task. Which means there will be some interesting data partnerships, or M&A consolidation, or you’re going to see some hyper specific model providers who go it alone and compete with the labs head to head. Likely all of the above.
In the meantime, we’re happy to be the only vendor in our space with a custom model that’s also objectively superior to everything else out there. And we’re excited to deploy it far and wide for the benefit of end customers everywhere. Our next announcement that’s coming very soon will help us do exactly that.
 | A guest post by
|
kisadhaalimansi941@gmail.com
Great article and I agree that moats in Ai will come down to context engineering and specifically weighted models and datasets. We in BoardX are building the AI Governance layer for governance and oversight designed to help organisations manage, monitor, and control their use of AI across the enterprise, maintaining compliance with the EU AI Act as deployers within a risk framework